Uno de los puntos más importantes para entender el rendimiento de un sistema multinúcleo es entender lo que es una topología de interconexión, que es la forma en la que está organizada la comunicación entre los diferentes elementos en un chip multinúcleo, sea este de configuración homogénea donde todos los núcleos son iguales o heterogénea, donde hay de diversos tipos, lo cual es normal a día de hoy. Es por ello que os hemos preparado un artículo sobre ello.
¿Qué es una topología de interconexión o de red?
En un sistema donde hay varios núcleos, hablemos de los núcleos de una CPU o de los núcleos de una GPU, nos encontramos con que los diferentes núcleos y unidades que lo componen requieren intercambiar datos y sincronizarse. Por lo que es importante escoger la topología de interconexión adecuada, ya que estas pueden tener un impacto significativo en el rendimiento, la latencia y la escalabilidad de la arquitectura.

El mayor handicap aquí son dos elementos, por un lado, el consumo energético del chip y por el otro el área, que tendrá que ver con la cantidad de elementos que podamos asignarle a la interconexión. Muchas arquitecturas no utilizan la topología de interconexión ideal por el hecho que el tamaño del chip y su complejidad en lo que al número de transistores se refiere sería demasiado alta y se saldría de presupuesto.
Hay que tener en cuenta que un mismo chip no usará una misma topología de interconexión e incluso puede usar varias al mismo tiempo de forma concatenada en un mismo chip.
Crossbar (Conmutador cruzado)
En un Crossbar cada uno de los componentes está directamente conectado con los demás. Esto hace que la complejidad de la red pase a ser de 2N donde N es la cantidad de componentes existentes.

El hecho de tener una conexión directa entre los elementos permite que varios núcleos se comuniquen al mismo tiempo sin interferencia con una latencia predecible y baja. No obstante, se trata del tipo de interconexión más costosa en área y consumo y requiere una gran cantidad de interconexiones que hace que sea difícil escalar a partir de cierto punto.
No en vano, el Crossbar no se utiliza para sistemas de más de 4 núcleos y todos los fabricantes para microprocesadores de 6 u 8 núcleos deciden optar por un Ringbus para simplificar el área y el consumo que supondría usar un Crossbar como tipología de interconexión.
Ringbus (Bus en anillo)
Un Ringbus es el tipo de topología de interconexión más usado a día de hoy en CPU y GPU, en ella los componentes se encuentran organizados en forma de un anillo. Donde en vez de haber interconexiones directas punto a punto, los datos han de recorrer el anillo hasta alcanzar su destino. El símil en la vida real que ayuda a entenderlo es el de una autopista radial o circular, donde los datos son los vehículos y las diferentes salidas son las interconexiones con los núcleos.

Esto convierte al Ringbus en una topología de interconexión simple y eficiencia en términos de área, ya que se requiere menos complejidad que el Crossbar al no necesitar tantas interconexiones directas. Sin embargo, esto tiene un coste, y es que con cada elemento que añadimos de más se aumenta el tiempo en que los datos recorren el anillo y con ello crece la latencia, por lo que a partir de cierto número de núcleos es contraproducente en términos de rendimiento.
Mesh (Red de malla)
Este tipo de topología de interconexión se ha puesto muy de moda últimamente al usarse de cara a crear NPU o unidades de cálculo matricial para el Deep Learning. En ella nos encontramos con que los diferentes núcleos o componentes están dispuestos en una cuadrícula, es decir, un matriz bidimensional donde uno de los componentes está interconectado con sus vecinos cercanos.
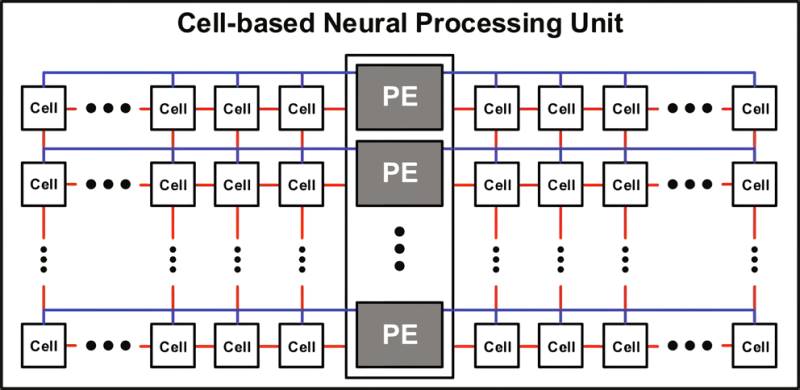
Esto permite añadir o quitar núcleos fácilmente y distribuir la carga por varias rutas, lo que evita a que existan contenciones y cuellos de botella. Sin embargo, al igual que Ringbus nos encontramos con que llegado a un punto no es eficiente añadir más núcleos por temas de latencia. Aparte de ser más difícil llevar a cabo la gestión de los datos en comparación con otras topologías de interconexión.
Bus compartido
Es la topología más simple de todas, se trata de que una única interconexión es utilizada por los componentes para acceder a la memoria para intercambiar datos. No obstante, a medida que más componentes requieren de acceder al bus, se crea más contención, sube la latencia y se trata de la topología de interconexión más ineficiente de todas.
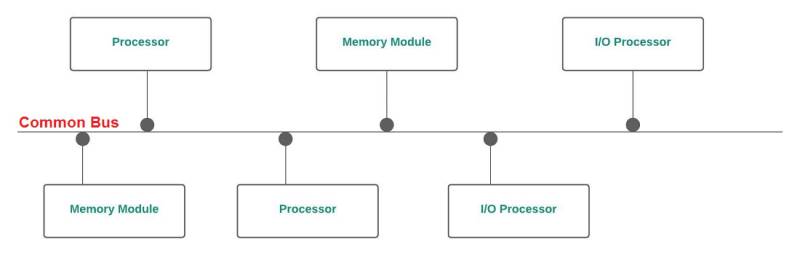
No obstante, era común en los primeros años de la informática y los primeros sistemas multinúcleo ni tan siquiera se permitían el uso de un Crossbar, sino de un bus compartido, lo que limitaba mucho su rendimiento, incluso cuando había solo dos núcleos en el sistema. A día de hoy se utiliza sobre todo en los chipsets, en especial por el hecho que no se puede dar todo el ancho de banda a todos los periféricos al mismo tiempo.
Estrella (NoC)
La topología en estrella o Network on a Chip es la que más vais a acabar viendo en un futuro como reemplazo del uso del Ringbus. El concepto es sencillo, todos los elementos están conectados a un elemento central que es el que gestiona todos los envíos de datos, por lo que es necesario un procesador central totalmente especializado que se encargue de gestionar el envío y la recepción de datos de la forma más eficiente posible.
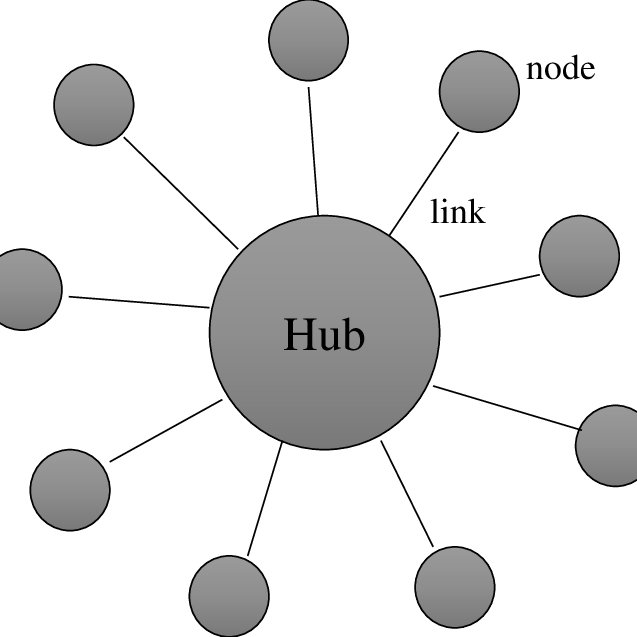
Es aquí donde entramos en la necesidades un controlador de red integrado, sin embargo, el desarrollo es el de los SmartNIC o controladores de red integrados inteligentes que entre otras cosas añaden las siguientes ventajas a una topología de interconexión en estrella:
- Un SmartNIC puede gestionar el tráfico de manera más eficiente que un simple conmutador central.
- Se encargan de gestionar la red, es decir, del procesamiento de los paquetes de datos, el cifrado, firewalling, etc.
- Puede gestionar mejor las políticas de seguridad y filtrar el tráfico que pasa entre los nodos periféricos
- Un SmartNIC puede implementar políticas de calidad de servicio para asegurar que los datos más importantes tengan prioridad, mejorando el rendimiento general de la red.
Obviamente, la capacidad del SmartNIC estará limitada por el área del chip y las necesidades de red del mismo.
¿Qué topología de interconexión dominará en el futuro?
Obviamente, es la topología en estrella con un SmartNIC central la que tiene más futuro de todas. De hecho, es una tendencia creciente en la industria de los semiconductores. La integración de capacidades de red avanzadas que proporciona un SmartNIC en un chip multinúcleo, hablemos de una CPU o de una GPU, nos ofrece varias ventajas en términos de rendimiento, eficiencia energética y reducción de la latencia. Esto es cuanto menos crucial para centros de datos, dispositivos embebidos y aplicaciones de inteligencia artificial.
| Marca | Modelos Destacados | Tecnologías Clave |
| NVIDIA (Mellanox) | BlueField, ConnectX | DPU, Offloading de NVMe, TCP/IP, RDMA, Seguridad avanzada |
| Marvell | Octeon, LiquidIO | Aceleración de red y cifrado, SDN, NFV, Seguridad de red |
| Broadcom | Stingray | Procesamiento de paquetes, Cifrado acelerado, Gestión de almacenamiento |
| Pensando Systems (AMD) | Pensando DSC | Redes SDN, Seguridad distribuida, Telemetría en tiempo real |
| Xilinx (AMD) | Alveo U25 | FPGAs personalizables, Procesamiento de baja latencia, Redes de alto ancho de banda |
| Silicom | Silicom SmartNICs | Offloading de seguridad, Virtualización, Redes de alto rendimiento |
Y eso es posible verlo con las adquisiciones y desarrollos que ha tenido la industria en los últimos años, lo cual podéis ver en la tabla de arriba. No tardaremos mucho en ver un SmartNIC en la parte central de un chip multinúcleo gestionando la interconexión interna entre los diferentes componentes de forma más eficiente que otras topologías de interconexión. Solo es cuestión de tiempo que esto ocurra y nuestra próxima CPU o GPU use dicha tecnología para mejorar la comunicación, la latencia y el consumo.