En los últimos años, ha habido un auge increíble del hardware para la IA, desde los popularizados por NVIDIA en sus GPU Tensor Cores, hasta una gran cantidad de Neural Processing Units o NPU en diversos teléfonos móviles e incluso ordenadores portátiles. Todo ello sin olvidarnos de otras arquitecturas que tienen las mismas funciones a mayor o menor escala. En este artículo os comentaremos los elementos básicos y en común de todos ellos para que entendáis mucho mejor su funcionamiento.
El auge del hardware para la IA
En los últimos años, hemos visto un avance imparable de la inteligencia artificial (IA) donde hemos podido observar cómo se ha convertido en una palabra en boca de todos y una tecnología omnipresente en el día a día. Y es que esta abarca varios sectores, donde los asistentes virtuales hasta los vehículos autónomos. Todo ello sin olvidarnos de los videojuegos, donde las tecnologías de reescalado de imagen a tiempo real y generación de frames han llegado para quedarse. Sin embargo, este cambio no hubiese sido posible sin la adopción masiva del hardware para la IA.

Históricamente, las CPU eran suficientes para ejecutar algoritmos de aprendizaje automático. Sin embargo, el Deep Learning (aprendizaje profundo), que usa redes neuronales profundas (de gran complejidad) y enormes volúmenes de datos. Por lo que requiere de una velocidad y una potencia de cálculo exponencialmente mayores. Es aquí donde entra el hardware para la IA, unidades especializadas que se han diseñado para optimizar dichas tareas.
El punto de inflexión llegó con NVIDIA Volta, una GPU pensada para el mercado de computación de alto rendimiento que añadió unidades especializadas para el Deep Learning a las que comercialmente llamaron bajo el nombre Tensor Cores. A partir de ese momento, la marca de Jen Hsun Huang añadió dichas capacidades a su plataforma de desarrollo CUDA y evolucionó a las tarjetas gráficas a que fueran motores clave para la IA.
Diversificación del hardware para la IA

Pese a su enorme popularidad, no solo los Tensor Core de NVIDIA son el único hardware para la IA que ha aparecido en los últimos años, sino que hay una gran variedad de tecnologías en el mercado que han democratizado tareas como traducción en tiempo real, reconocimiento facial, asistentes por voz, generación de imágenes y texto y muchas otras aplicaciones en el día a día.
- Tensor Cores: introducidos por NVIDIA en sus GPU y copiados posteriormente por Intel (XMX) y AMD (Matrix Core Units).
- TPU (Tensor Processor Units): de uso exclusivo para Google, creados para acelerar la IA desde la nube.
- NPU (Neural Processing Unit): implementadas en los chips principales (SoC) de los teléfonos móviles para la realización de inferencia sencilla a través de la IA, que es útil, pero que no requiere mucha potencia.
- ASIC (Application Specific Integrated Circuit): chips o unidades altamente especializadas en algoritmos de aprendizaje concretos, se usan en soluciones muy específicas y muchas veces se implementan en forma de FPGA.
Tal diversificación del hardware para la IA se debe, por un lado, a la demanda de mayor potencia de cálculo. Por el otro lado, a la necesidad de adaptar las soluciones a diferentes contextos. Desde el entrenamiento masivo en centros de datos hasta la inferencia ligera en dispositivos móviles. Por lo que cada tecnología tiene un papel específico que jugar.
Matrices y tensores: ¿qué son y para qué sirven?
Una vez hemos hecho una pequeña introducción e identificado el hardware para la IA, nos toca hablar de los puntos en común en todos ellos, el cual es el uso de matrices o tensores. Por lo que primero empezaremos explicando qué es una matriz, la cual no es más que un conjunto de números organizados en una tabla.

Ahora bien, hemos de entender que una matriz es un tensor de dos dimensiones, un vector es un tensor de una sola dimensión y se les llama coloquialmente como tensores cuando son de 3 dimensiones. Si, por ejemplo, almacenamos una imagen RGB según sus componentes de color básicos (rojo, verde y azul), entonces la información estaría organizada en tres dimensiones que son ancho, alto y componentes. Pues bien, como ya habréis observado, un Tensor puede almacenar grandes cantidades de datos dentro del mismo.
Las redes neuronales realizan millones de operaciones matemáticas con estos tensores para entrenar modelos y realizar predicciones, realizando para ello una gran cantidad de operaciones matemáticas a gran velocidad, pero para poder hacerlo con la suficiente soltura no se vale el uso de unidades escalares, que trabajan con un solo valor por instrucción, y tampoco vectoriales o SIMD, que trabajan con tensores de una sola dimensión. De ahí la necesidad del desarrollo del hardware para la IA.
Arrays sistólicos: la base del hardware para la IA
Da igual, si hablamos de Tensor Cores o NPU, todo hardware para la IA se basa en una organización en común, la cual es la ideal para el cálculo con matrices/tensores. A esta configuración la llamamos arrays sistólicos y son clave para entender cómo funciona el hardware para la IA. Para empezar, en un array normal, cada uno de los componentes se encuentra conectado a una memoria o registro común, sin embargo, si hablamos de un array sistólico, este bombea los datos a sus vecinos y los recibe desde sus vecinos, solo las unidades que se encuentran en los extremos del array sistólico tienen conexión con un registro.
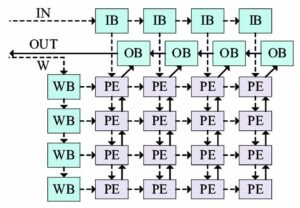
Todos los arrays sistólicos tienen las siguientes características en común:
- Cada unidad realiza sus operaciones al mismo tiempo que el resto, lo que permite un alto rendimiento.
- Los datos se mueven entre las diferentes unidades del array sistólico siguiendo patrones predefinidos, lo que minimiza la complejidad del control y la latencia.
- Dado que los datos no viajan de vuelta ni tan siquiera a una memoria caché o una local, sino a la unidad de ejecución que tienen al lado, su consumo energético es muy reducido en comparación con arquitecturas tradicionales.
Hemos de partir del hecho de que el Deep Learning depende de operaciones con tensores repetitivas, como la multiplicación y la suma. Nos pueden parecer muy banales, pero los arrays sistólicos, gracias a su configuración, pueden realizar dichas operaciones decenas de veces más rápido. Solo hay que ver las GPU de NVIDIA y ver la tasa de Tensor TFLOPS que es la capacidad de cálculo en comparación con la de las unidades CUDA (FP32). Por lo que los arrays sistólicos son el corazón del hardware para la IA gracias a su capacidad para realizar cálculos repetitivos de manera eficiente.
Un ejemplo práctico: Tensor Cores y similares
Los Tensor Cores en las GPU de NVIDIA son unidades de ejecución dentro del núcleo de la GPU, esto significa que no son núcleos por sí mismos, sino que varios de ellos forman parte de un núcleo y comparten el acceso con los registros, la memoria local y la caché de primer nivel de datos junto a las unidades SIMD. Por lo que un conjunto de instrucciones podrá usar total, parcialmente o ignorar a este hardware para la IA, por lo que su principal ventaja es que pueden realizar operaciones conjuntas SIMD+Tensor a gran velocidad.

Lo que hace impresionantes a los Tensor Cores es su escala. Por ejemplo, en las arquitecturas Volta y Turing (RTX 20) que fueron las primeras en implementarlos, cada núcleo de la GPU tenía 8 Tensor Cores, uno por subcore compartiendo recursos con la unidad SIMD. Pues bien, cada una de estas unidades puede procesar un tensor de tres dimensiones (4 x 4 x 4) o uno de dos dimensiones (8 x 8). Esto se traduce en que en cada núcleo de dichas GPU hay 512 unidades de cálculo distintas para operar con matrices/tensores.
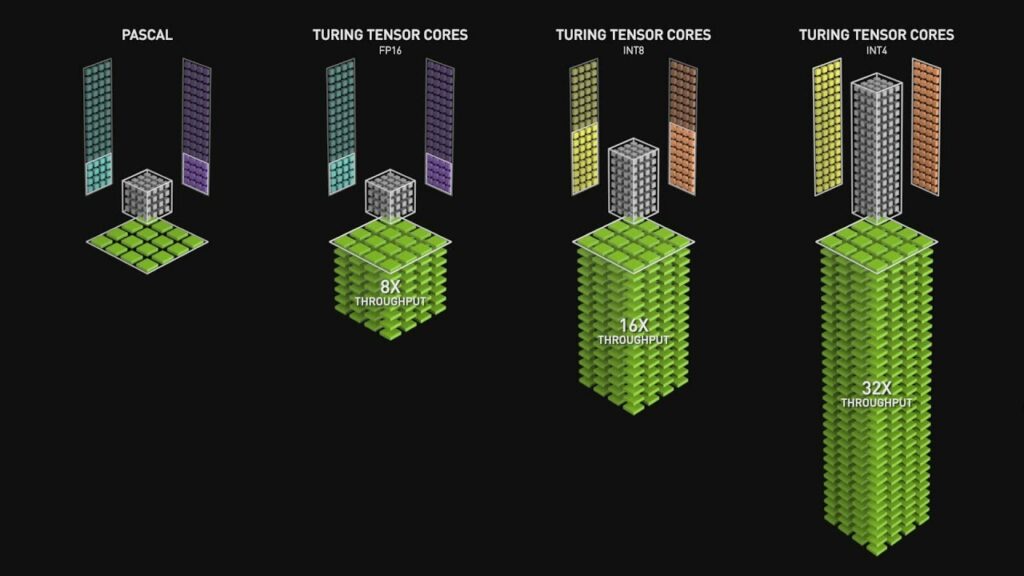
La primera generación de Tensor Cores en NVIDIA fue un salto 8 veces superior en la potencia de cálculo, no solo eso, sino que sí se reducía la precisión de los datos. La potencia de cálculo de los arrays sistólicos se duplicaba varias veces. Con esto ya os podéis imaginar el aumento en escala de la potencia de los Tensor Cores en comparación con las unidades SIMD. Es por ello que han sido copiados posteriormente por Intel (unidades AMX en sus CPU Xeon y XMX en sus GPU ARC), por AMD (Matrix Core Units en CDNA y el hardware para IA de la PS5 Pro).
Neural Processing Unit
Las NPU son el otro tipo de hardware para la IA que se ha popularizado en los últimos años, especialmente en los teléfonos móviles, por lo que no llegan a la escala de cálculo de los Tensor Cores y similares. De ahí a que no existan centros de datos o superordenadores que usen miles de NPU, ya que estas están más especializadas en trabajar en consumos mucho más bajos. Su uso empezó en los teléfonos móviles, pero ahora se han vuelto una parte esencial en los ordenadores gracias a ser un requisito mínimo para tecnologías como Copilot en Windows 11, que requieren una potencia de 40 TOPS o superior.
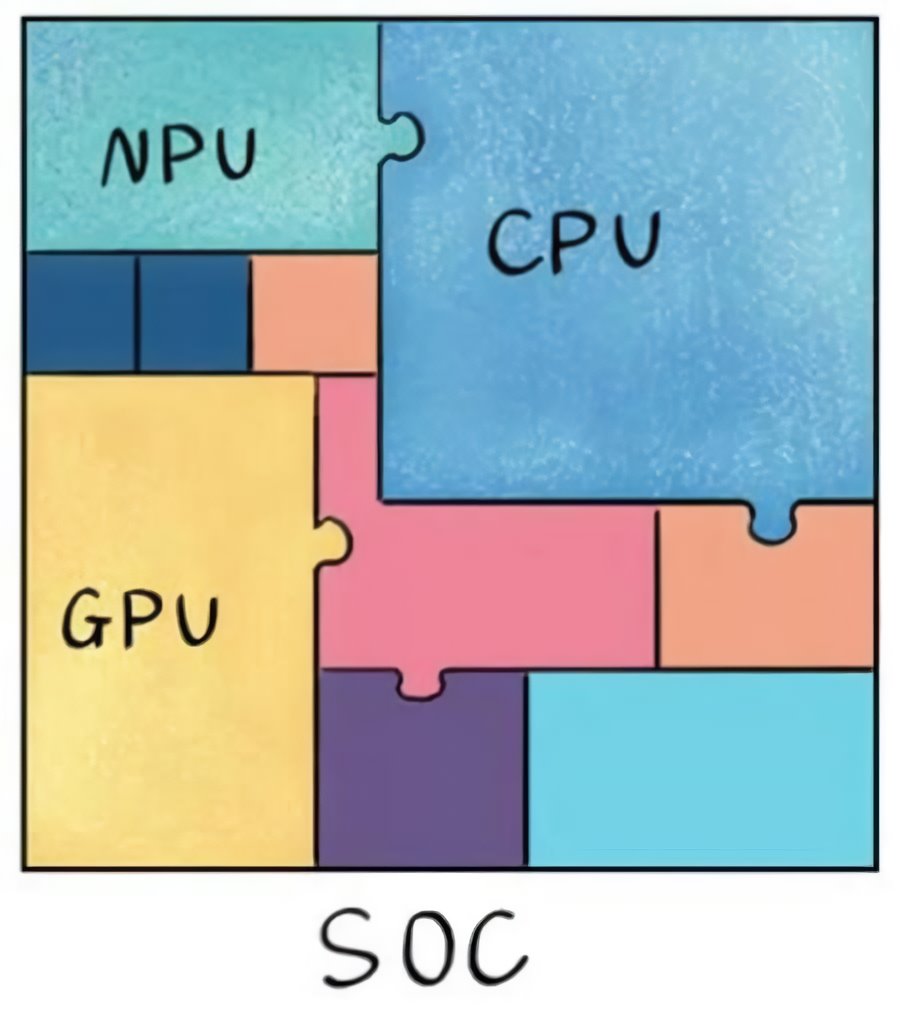
Su principal diferencia es que pese a que sus unidades de cálculo también son array sistólicos, al contrario que los Tensor Cores no se trata de unidades de ejecución dentro de una CPU o una GPU, sino que son una unidad de procesamiento completa, por lo que están definidas por un set de instrucciones y la capacidad de captarlas en memoria y procesarlas como si fuese una unidad de procesamiento. En realidad, junto a la GPU y las unidades de procesamiento de imagen, son una de las muchas que acompañan a la CPU en un chip.
En realidad, los Tensor Cores son útiles cuando se trabajan con conjuntos de datos masivos, dado que como hardware para la IA, las NPU son limitadas, pero tienen la capacidad de poder usarse en hardware de bajo consumo y permiten el uso de redes neuronales sencillas. Es más, a la hora de realizarlas son más eficientes que una GPU desde el punto de vista energético, por lo que no es de extrañar que se busquen estandarizar ambos tipos de unidades.
ASIC para la IA
Existen situaciones donde un dispositivo requiere de un tipo concreto de algoritmo de Deep Learning y nada más, para ello es una pérdida de tiempo y recursos usar un Tensor Core o una NPU. Es en este punto donde entran los ASIC para la IA que se utilizan para soluciones muy específicas. Para que entendáis lo que son en general este tipo de instrucciones, tenéis que saber que sus instrucciones están microcableadas, por lo que no son programables y no tienen un set de instrucciones. Lo único que hacen es que, a partir de unos datos de entrada, realizan siempre las mismas instrucciones retornando unos datos de salida.

Dado que no son programables, siempre harán lo mismo una y otra vez, por lo que requieren una circuitería mucho más sencilla, pero no pueden evolucionar. Su uso no es muy generalizado desde el momento en que la versatilidad y potencia de las NPU y los Tensor Cores es mayor. No obstante, muchas empresas suelen implementar sus ASIC en FPGA para acelerar ciertas tareas comunes. En todo caso, son la peor solución de todas y la más primitiva, lo que no significa que no se use cuando, a niveles de coste energético y económico, son la mejor solución a un problema.