Si hace unos días os hacíamos un resumen de las novedades que traen consigo las RTX 50 de NVIDIA bajo arquitectura Blackwell, esta vez le toca el turno a las AMD Radeon RX 90×0 bajo arquitectura RDNA 4. Donde, al igual que sus rivales, nos encontramos con una mejora incremental de la anterior generación, pero, al igual que ocurre con la PS5 Pro de Sony, con una mejora importante en el rendimiento de cara a la IA y el Ray Tracing. Se trata de una arquitectura de transición, antes de dar un salto a la arquitectura UDNA. La cual se usará en sistemas como PlayStation 6 y la futura Xbox, aunque ya incluye algunos elementos provenientes de CDNA, lo que la convierte en una arquitectura de transición, no por ello menos interesante.
Nota de la redacción: debido al Hot Chips de 2025, donde AMD ha dado nuevos datos de la arquitectura de RDNA 4, hemos decidido actualizar este artículo.
AMD vuelve a las GPU monolíticas con sus Radeon RX 90×0
En el pasado CES de enero de 2025, AMD dio un adelanto de sus próximas tarjetas gráficas, basadas en la arquitectura RDNA 4, y que se lanzarían bajo el nombre comercial de Radeon RX 90×0, siendo las primeras que saldrán al mercado las más potentes de la gama: RX 9070 XT y RX 9070. La sorpresa fue mayúscula cuando la empresa de Lisa Su confirmó los rumores en que no solo no van a competir de tú a tú frente a la gama alta de NVIDIA, sino que anunciaron que no tenían planes de superar en rendimiento bruto a la RX 7900 XTX, la tarjeta gráfica más potente de la anterior generación. No obstante, esto tiene cierta trampa, como veréis más adelante cuando tratemos las mejoras en Ray Tracing e inteligencia artificial.

En todo caso, hemos de ponernos en situación y tener en cuenta el rendimiento de la arquitectura RDNA 3 en el mercado de las tarjetas gráficas, dejando a AMD en la peor situación posible que no es otra que NVIDIA teniendo el 90 % del mercado. Esto explica el motivo por el cual no han querido continuar con el planteamiento de una GPU por chiplets o disgregada en RDNA 4 para preferir volver al modelo tradicional, ya que el rendimiento obtenido no compensa.
Organización general de las arquitectura RDNA
En principio, el diseño general de las diferentes generaciones RDNA de AMD es el mismo, con pequeñas mejoras incrementales que se han visto en el tiempo. No obstante, nos da la sensación de que, una vez terminada RDNA 2, el Radeon Technology Group tomó dos caminos distintos. El primero de ellos derivó en la arquitectura RDNA 3 usada en las tarjetas gráficas RX 7×00 y las gráficas integradas en las CPU Ryzen de la propia AMD. La segunda será la GPU principal de la serie RX 90×0 para tarjetas gráficas dedicadas, aunque no se espera su aparición en futuras iGPU, al menos por lo que se sabe hasta el momento.

La organización general sigue siendo la misma que las tres anteriores generaciones de RDNA, pero, claro está, mejorando ciertas partes clave para conseguir un salto en rendimiento considerable tanto si hablamos de rasterización como de ray tracing. En especial en este último donde AMD ha decidido coger carrerilla y recortar enormemente la enorme diferencia que tenían con NVIDIA, si bien todavía siguen por debajo en rendimiento para las escenas que utilizan trazado de rayos, concentrándose la mayoría de los cambios importantes en los núcleos de la GPU.
Compresión y descompresión interna
Uno de los secretos de RDNA 4 que AMD ha revelado en el Hot Chips de 2025, es la existencia de mecanismos de compresión y descompresión interna entre las diferentes memorias y unidades internas. Algo que desconocíamos anteriormente y que es clave de cara a la reducción en el consumo energético y la eficiencia de la GPU. Se ha de aclarar que el proceso es totalmente invisible a los programadores e incluso al propio driver al hacerse internamente en el hardware.
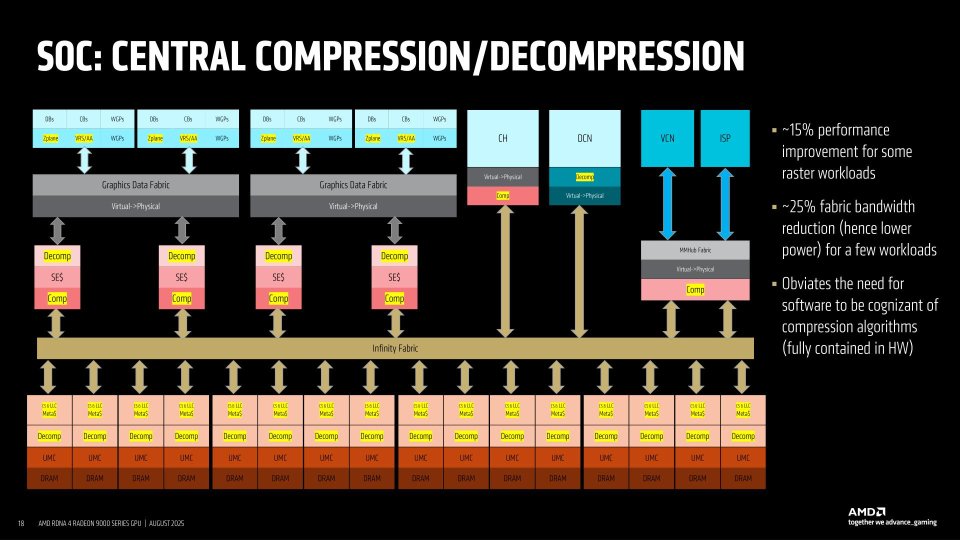
La utilidad es sencilla, asegurarse que la mayor cantidad de datos e instrucciones posible se encuentre en la memoria caché y las memoria locales, reduciendo así el impacto de tener que buscar datos a la memoria principal y aumentando de paso el rendimiento. Y como hemos dicho, todo ello se procesa de manera interna en la GPU de forma que el driver o el programa no tienen que actuar y a la suficiente velocidad como para no perjudicar el rendimiento general.
El núcleo de la GPU en RDNA 4
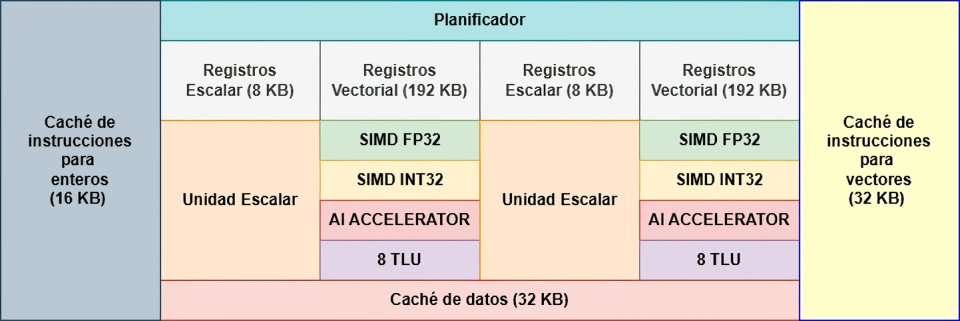
La organización de los núcleos de la GPU, conocidos como Compute Units es doble en el caso de las arquitecturas RDNA, ya que tenemos dos núcleos compartiendo una serie de elementos en común tal y como se puede ver en el diagrama de abajo donde la caché de instrucciones, la memoria local compartida y la caché de escalar están compartidas, mientras que el resto de elementos se mantienen intactos. Como se puede ver no hay cambios aparentes respecto a RDNA 3.
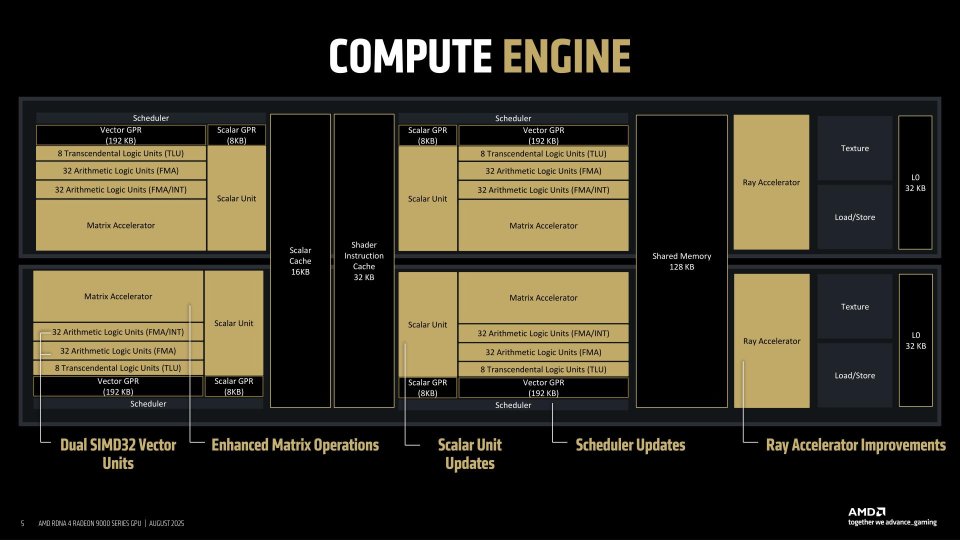
Sin embargo, los pequeños cambios que existen son poderosos, en especial en dos áreas: por un lado en el planificador de cada uno de los núcleos, el cual ahora tiene la capacidad de asignar dinámicamente los registros para aprovechar aún más la capacidad de trabajo de las unidades SIMD, el segundo son las nuevas unidades de intersección de rayos, las cuales son las mismas que utiliza PS5 Pro y que traen consigo una serie de mejoras que consiguen aumentar considerablemente el rendimiento de cara a ejecutar escenas con Ray Tracing en comparación con RDNA 3 y anteriores.
Unidades de ejecución (ALU)
Estas no han evolucionado respecto a generaciones anteriores de RDNA, si bien mantienen la capacidad VLIW2 de RDNA 3, AMD ha preferido no anunciarla mucho después del fiasco en RDNA 3 donde muchos hablaban del doble de TFLOPS sin entender absolutamente nada de lo que ocurría. El truco en ese caso es que hay momentos en que aprovechando que las ALU pueden operar con 3 operandos (más que nada por la capacidad FMADD) pues hay casos especiales donde el tener ciertas unidades de ejecución libres permite unir unir dos instrucciones en una y solventarlas en el tiempo en que se soluciona una sola instrucción.
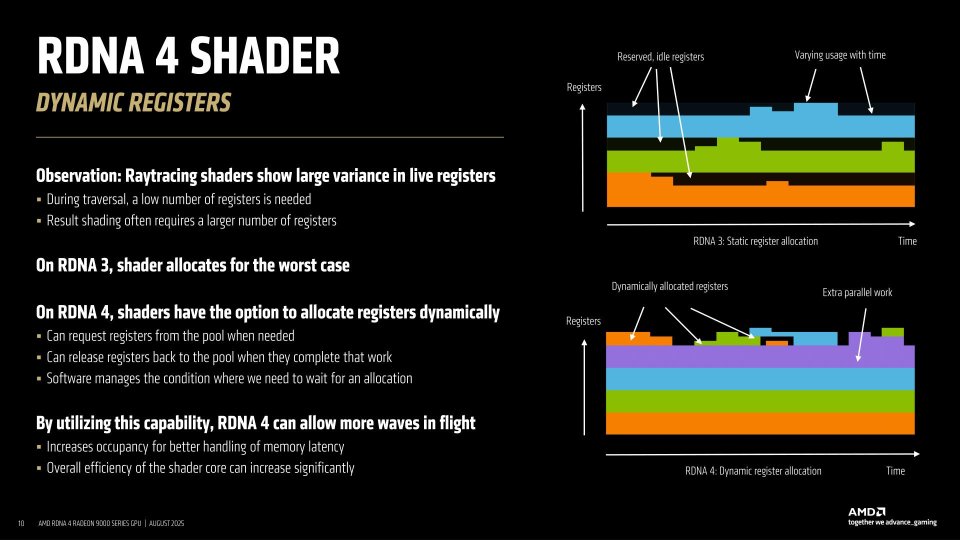
Registros dinámicos
el primero de ellos es la relocalización dinámica de registros. Para entender su importancia hemos de partir del hecho de que las GPU tienen una gran cantidad de registros, donde cada registro contiene una instrucción + dato donde el dato puede ser la misma información a procesar o en su defecto puede contener la dirección de memoria de donde se encuentre el dato, la cual se buscará en la caché L1 y luego en la jerarquía de caché hasta encontrarlo.
Pues bien, imaginad que estáis despachando en una carnicería y que cada cada cliente tiene un ticket que es un registro, lo que os interesa es ir atendiendo clientes ya que hay una larga cola y si no tenéis a nadie a quien darle el servicio no hacéis nada, pues lo que hacen las GPU es eso, van atendiendo largas colas de clientes mientras tanto.
Ahora vamos a complicar un poco más las cosas, supongamos que cada cada operario en la carnicería es una ALU, por lo que si hay pocos clientes habrá operarios que no harán nada en esos turnos. Pues bien, ese es un problema muy común en las GPU que en RDNA 4 AMD ha querido solventar con la reasignación dinámica de registros. El cual consiste en una nueva forma de usar los registros asignados a las unidades SIMD, los llamados registros vectoriales, los cuales tienen un tamaño de 192 KB por unidad SIMD y son también conocidos como VGPR.
No vamos a entrar en detalles muy técnicos, el problema de cuando tenemos varias olas activas, pero sin ocupar todos los registros, es que la parte que no tiene trabajo no puede terminar ni hacer nada hasta que el resto de sus compañeras hayan terminado su trabajo. En el símil de la carnicería es como tener en la puerta una tanda de clientes esperando en la puerta y no poderlos atender esperando a que tus compañeros terminen de servir a los clientes actuales. Pues bien, los registros dinámicos evitan esto. Esto se traduce en que hay más operarios/ALU trabajando al mismo tiempo, aumentando el rendimiento.
Calculo matricial/Deep Learning
El mayor jarro de agua fría que nos hemos llevado con RDNA 4 es el hecho de que la arquitectura no soporta las llamadas Matrix Core Units de CDNA, las cuales no son más que la versión de los Tensor Cores de NVIDIA, pero en una GPU de AMD. Sino que al igual que con RDNA 3 de nuevo tenemos a las unidades SIMD realizando instrucciones WMMA, por lo que la potencia de cálculo en este aspecto sigue siendo más baja que la de NVIDIA, sin embargo, entendemos que el añadir una unidad de este tipo supone reorganizar internamente los núcleos de la GPU por completo. Un vistazo rápido a la documentación de la ISA de RDNA 4 nos lo confirma:
Las instrucciones de multiplicación-acumulación de matrices por ondas (Wave Matrix Multiply-Accumulate, WMMA) proporcionan aceleración para las operaciones de multiplicación de matrices. Cada instrucción WMMA o SWMMAC (WMMA dispersa) realiza una única operación de multiplicación de matrices utilizando los datos en los registros VGPR, que contienen una matriz A, B, C y D respectivamente. Una de las matrices se distribuye a lo largo de todos los carriles (lanes), es decir, no hay una matriz por carril. Las instrucciones se codifican utilizando el formato de codificación VOP3P.
¿Cómo lo hace entonces si carece de unidades Tensor? Las operaciones con matrices no requieren tener todos los datos en cada momento. Hemos de partir de que cuando se multiplican dos matrices, por ejemplo de 16×16 una y deñl mismo tamaño la otra, el resultado también es una matriz de 16×16, lo cual hace un total de 256 operaciones.

Para explicarlo bien, vamos a hablar cómo se operan las matrices en álgebra, tomando como ejemplo las más sencillas, la de 2 x 2. Donde para obtener los valores de la matriz C las operaciones son las siguientes:
- c(1,1)=a(1,1)⋅b(1,1)+a(1,2)⋅b(2,1)
- c(1,2)=a(1,1)⋅b(1,2)+a(1,2)⋅b(2,2)
- c(2,1)=a(2,1)⋅b(1,1)+a(2,2)⋅b(2,1)
- c(2,2)=a(2,1)⋅b(1,2)+a(2,2)⋅b(2,2)
Dado que en un array sistólico los núcleos se conectan entre sí tanto en vertical como en horizontal, hacer dichas operaciones en vertical y horizontal es mucho más fácil. En cambio lo que se hace internamente en las instrucciones WMMA en RDNA 4 es reordenar de tal manera que cada operación simple es asignada a una ALU, no obstante, tanto RDNA 3 como RDNA 4 utilizan un truco lo que se llama una caché de reutilización de operandos para acelerar ciertas instrucciones.
Operand reuse cache
Lo habitual, y da igual el tipo de núcleo, a no ser que el dato se encuentre codificado en la misma instrucción y se pueda acceder de forma directa en el registro, lo que hará la ALU será leerlo de la cache de datos. El problema viene cuando hemos realizado ya un calculo y queremos reutilizar su resultado para el siguiente, que hay de leer de nuevo de la caché de datos. Pues bien, una ventaja que AMD añadió a partir de RDNA 3 con tal de acelerar las instrucciones WMMA es la llamada Operand Reuse Cache, la cual se trata de una pequeña memoria caché más cercana a la ALU de la unidad SIMD, la cual permite almacenar temporalmente un valor ya calculado.
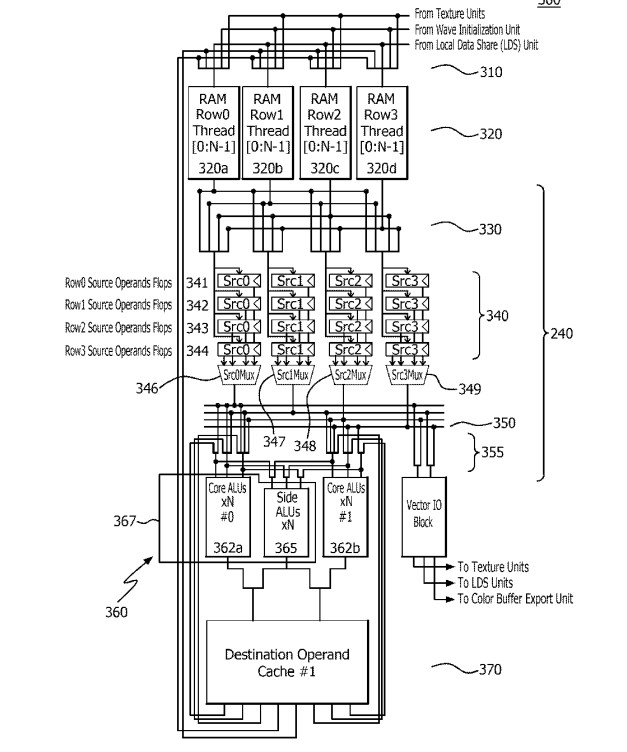
Curiosamente, hace ya varios años AMD patentó el concepto bajo el nombre de Super-SIMD, y cuando decimos años nos referimos a que publicaron la patente mucho antes del lanzamiento de la primera generación de RDNA, es más, por aquel entonces muchos creímos que era una de las características de la nueva arquitectura, pero tuvimos que esperar a RDNA 3 para verlo, por lo que esto es algo de lo que carece PS5 Pro.
Para entender su utilidad, hemos de entender que a la hora de calcular el componente de una matriz nos encontramos con el hándicap de que cada ALU (hilo/lane) es independiente y no pasa datos a otras ALU durante la ejecución. Si bien puede leer información de la caché de datos o de la memoria local en en núcleo de la GPU, esto consume ciclos de lectura y escritura, lo que hace menos eficiente la operación. Si bien la LDS es utilizada tarde o temprano, la clave se encuentra en una serie de registros adicionales donde se pueden acumular temporalmente resultados y utilizarse como operandos.
Por ejemplo, a la hora de calcular a(1,1)⋅b(1,1) esto lo haría una sola ALU, el resultado se acumularía en el registro adicional, para el cálculo de a(1,2)⋅b(2,1) se haría en una segunda ALU y se acumularía en el registro adicional. Luego, una de las dos ALU realizaría la suma correspondiente leyendo dichos registros adicionales. Sin necesidad de copiar los resultados en la memoria local del núcleo.
Ray Accelerator Unit
Con cada nueva generación, los RT Core de las GPU de NVIDIA han duplicado su capacidad de cálculo medida en la cantidad de intersecciones que pueden hacer, si bien en muchos casos han tirad de trucos, las RTX 50 tienen una capacidad para calcularlas que 16 veces mayor que las RTX 20 por núcleo y ciclo de reloj. Pensad que en el trazado de rayos el algoritmo siempre consiste en proyectar un rayo desde la cámara o desde la fuente de luz y comprobar si impacta con un objeto en escena, esto se hace millones de veces y es importante una alta tasa. No obstante, esto no se hace sobre la escena en 3D, sino sobre una representación en forma de estructura de datos llamada BVH, el cual no es otra cosa que un árbol binario. Y creednos, al contrario de lo que ocurre con las CPU donde estas tienen potentes unidades de predicción de saltos, el recorrer un árbol BVH para un núcleo tradicional de una GPU es un infierno.
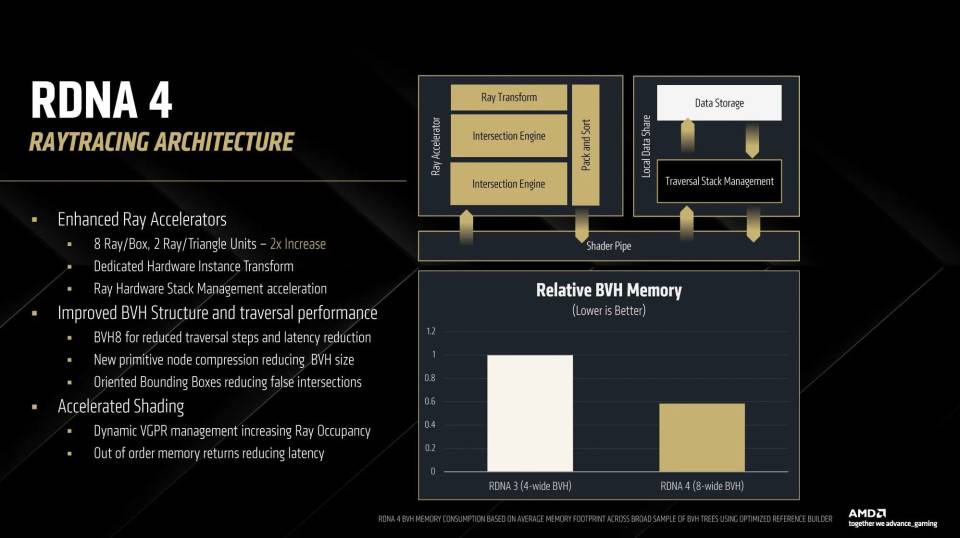
AMD por su parte decepciono desde RDNA 2, no le dieron importancia al Ray Tracing, afectando negativamente a las consolas de videojuegos de paso. Simple y llanamente obviaron el añadirle la capacidad de recorrer el árbol BVH, cargando la responsabilidad a las unidades SIMD, el rendimiento termino siendo patético. Por suerte en RDNA 3 dicha falta se soluciono, pero el salto fue decepcionante, solo un 50% más en la cantidad de intersecciones. Por lo que uno esperaría que en RDNA 4 al menos AMD solucionará el problema, sin embargo, para ver cambios importantes parece que tendremos que esperar a UDNA. ¿Por qué? Por el hecho que lo que ha hecho AMD ha sido hacer trabajar en paralelo dos de las unidades de RDNA 4 y les ha dado la capacidad de trabajar en conjunto para poder manejar un árbol BVH8 o de recorrer en paralelo un árbol BVH4.
Object Bounding Boxes
No obstante, AMD no se ha limitado a duplicar las unidades de RDNA 3, sino que de cara al trazado de rayos han añadido una serie de mejoras adicionales:
- Se ha reducido la información que almacenan los BVH en memoria, permitiendo que este sea más pequeño lo que reduce la cantidad de acceso a la VRAM por el hecho de que habrá más partes de la estructura de datos que cabrán en la caché. Desde el momento en que las Ray Accelerator Units son las mismas que en PS5 Pro, la GPU de la consola potenciada de Sony también se beneficia de ello.
- En RDNA 4, AMD ha introducido los OBB, lo cual permite rotar las cajas delimitadoras en las que se encuentra almacenada la geometría dentro del BVH. Este truco permite reducir el espacio vació y evita los falsos positivos en las intersecciones. Dicha rotación no es realizada por las unidades SIMD, sino por las unidades de cálculo internas de la Ray Accelerator Unit, las cuales sí que han tenido cambios respecto a las de RDNA 3. Para empezar disponen de una ROM de solo 800 bytes, la cual contiene como realizar los cálculos de las 104 posibles matrices para rotar las cajas del BVH, al mismo tiempo han añadido una pequeña unidad capaz de realizar transformaciones geométricas de 3×3 liberando a las unidades SIMD de tener que rotar las cajas.

¿Para que sirve todo esto? Tanto en RDNA 2 como en RDNA 3 el BVH era del tipo AABB donde las cajas estaban alineadas a los ejes, esto permitía que se pudieran calcular muy rapidamente, pero si había un elemento de la geometría que estaba rotado respecto a los ejes esto provocaba un falso positivo, lo cual es una caja en el BVH en la que la Ray Accelerator Unit entrará y no habrá nada. Hay que tener en cuenta que cuando se recorre el árbol BVH desde una posición global de la escena para luego ir a lo más concreto el sistema desconoce lo que hay en los nodos inferiores. La idea de poder rotar para el BVH las cajas reduce la cantidad de falsos positivos y permite orientar la potencia a lo que es realmente importante.
Memoria fuera de orden
Desde el momento en que la memoria no calcula nada, esta no puede ser fuera de orden, pero si que pueden serlo las peticiones a memoria y aquí entramos en otro de los puntos únicos de RDNA 4 junto a los registros dinámicos, que es la memoria fuera de orden. La idea no es otra que permitir que las peticiones de las diferentes Compute Units al controlador de memoria integrado de la GPU se puedan resolver de una forma más eficiente.

El problema que existe cuando las peticiones a memoria se hacen en orden, es que en un sistema que trabaja en paralelo tenemos varios accesos a memoria al mismo tiempo, no en vano tenemos varios chips de memoria y en el caso de la GDDR6 2 canales por chip de memoria. Claro está que si una petición anterior ha sufrido un miss y tarda más de la cuenta, el resto de peticiones en la cola ya solucionadas se han de esperar para dar resultados. En RDNA 4 han cambiado esto y los resultados desde memoria se devuelven no según el orden de petición, sino según si se ha obtenido ya el dato o no.
Esto reduce enormemente la latencia del acceso a los datos, y si bien los núcleos de la GPU esconden bien la latencia, su método tradicional no es infalible y hay momentos en los que tienen que esperar al resultado que les llegue desde memoria. Tradicionalmente lo que se usa es el método Round-Robin, el cual da un tiempo en número de ciclos para solventar una ola, si no puede la deja en reserva y adelanta la siguiente tanda. El problema es que hay olas que dependen del resultado de otras y se llega al punto en que una vez solucionadas las olas más rápidas solo quedan las lentas, de ahí a que la memoria fuera de orden sea tan importante.
RDNA 4 versus GPU de PS5 Pro
Pese a compartir algunos elementos en común, hemos de recordar que la GPU de PS5 Pro no se basa en la arquitectura RDNA 4, debido a que, a nivel de núcleo de la GPU, así como del chip en general, hay una serie de diferencias importantes entre ambos. La más clara de todas es la existencia de la Infinity Cache, una memoria caché de tercer nivel de 64 MB de tamaño que es inédita por el momento en todos los chips de AMD para consola. No obstante, dicha diferencia ya existía entre PC y consolas desde RDNA 2, aunque en todo caso no es el único cambio a nivel global de la GPU.

En realidad lo único que hereda de RDNA 4 la GPU de PS5 Pro, la cual recordemos que es una mejora de RDNA 2, es la nueva unidad de trazado de rayos, pero nada más. Los registros dinámicos y la memoria fuera de orden sigue siendo exclusiva de RDNA 4. No solo eso, sino que la forma de procesar el Deep Learning cambia, ya que PS5 Pro utiliza una instrucción de convolución especial de 3 x 3 para el PSSR, ya que no dispone de las extensiones WMMA de RDNA 3 en adelante, las cuales son mucho más generalistas, mientras que Sony ha decidido ir por algo más especifico de cara al escalado de superresolución. Todo ello se traduce en que la GPU de PS5 Pro por las carencias de ciertos elementos no alcanza el rendimiento de una tarjeta gráfica con RDNA 4 y por lo tanto no son directamente comparables.