Las CPU con arquitectura Zen se han vuelto en los últimos años entre las más utilizadas, no en vano, se encuentran en las consolas de la actual generación y han representado el retorno de AMD a la cima en el mundo de los microprocesadores. Dado que teníamos pensado hablaros de cómo funciona un microprocesador contemporáneo, después de explicaros a varios clásicos, hemos pensado hacerlo con esta familia de CPU, la cual usaremos en un futuro como referencia comparativa con otros diseños. Al mismo tiempo aclaramos que este artículo no es comparativo, ni tan siquiera dentro de la misma familia en cuanto a rendimiento, por lo que no veréis referencias en cuanto a diferencias de rendimiento, ya sean globales o comparando núcleo por núcleo o ciclo por ciclo.
FrontEnd en una CPU contemporánea

El Frontend de un procesador es la parte de la microarquitectura encargada de transformar el flujo de instrucciones del programa en un formato interno que pueda ser procesado eficientemente. En esta etapa se decide qué instrucciones deben buscarse, cómo se resuelven las bifurcaciones del código y de qué manera se alimenta al resto del procesador. Su objetivo es mantener un flujo constante y predecible hacia las unidades posteriores, ya que cualquier interrupción o latencia aquí se traduce en una pérdida directa de rendimiento.
La unidad de predicción de saltos
En una CPU contemporánea, la primera unidad que aparece en escena es la unidad de predicción de saltos, la cual controla el flujo de las instrucciones controlando si la siguiente es un salto o no, es decir, si continuará en la siguiente dirección de memoria o se realizará un cambio en el contador de programa, aparte de que también tendrá en cuenta si el salto se dará por una condición o será incondicional. El primer microprocesador con el set de registros e instrucciones x86 en tener una unidad de este tipo fue el Intel Pentium, desde entonces todas las arquitectura de Intel y AMD han dispuesto de esta unidad y se ha convertido en una de las más importantes, al ser la primera unidad que participa en la ejecución de las instrucciones y el punto de partida en el Frontend, incluso por delante de la Fetch Unit o Unidad de Captación.

Aquí es importante el Branch Target Buffer o BTB, esta memoria contiene el historial del resultado de los últimos saltos que se han realizado, independientemente de si se han tomado o no, así como la dirección de destino de dichas instrucciones. A partir de la familia Pentium Pro/Pentium II/Pentium III la estrategia dejó de ser esperar a la confirmación de salto para ejecutar este de forma aislada independientemente de si la condición era cierta o no, para confirmar o desmentir la rama del código tomada. la BTB era la memoria encargada de encargarse de que los saltos ya producidos y con resultado ya conocidos no volviesen a repetirse de nuevo.
BTB multinivel
En realidad el BTB funciona como una memoria cache tradicional, y al igual que esta cuando su tamaño se vuelve demasiado grande resulta lenta recorrerla. El concepto de un Branch Target Buffer compuesto por varios niveles se lo debemos al Intel Sandy Bridge, el cual introdujo una organización de dos niveles al BTB de su unidad de predicción de saltos. En realidad hablamos de una jerarquía de saltos en la que:
- El primer nivel del BTB es una memoria pequeña y rápida que contiene los saltos más recientes y frecuentes.
- El segundo nivel, es más grande y por lo tanto almacena más entradas, pero es más lenta.
El funcionamiento es igual que el de una memoria caché, cuando la unidad de predicción de saltos encuentra una instrucción de este tipo, lo primero que hace es buscar en el primer nivel, si no la encuentra, entonces hace un BTB miss para consultar en el segundo nivel. En el caso de que la encuentre, lo que hará será moverla al primera nivel, si no la encentra entonces deberá calcular la dirección de destino del salto de forma normal.
Predicción de saltos mejorada en el AMD Zen
No obstante, con la aparición de la arquitectura Zen, AMD le dio una vuelta de tuerca adicional a la unidad de predicción de saltos y su BTB. El primer cambio es que pasaron de almacenar una dirección de destino por línea del BTB a poder almacenar dos. Esto era importante, ya que podría ocurría que en una misma captación de memoria hubiese dos saltos condicionales, lo que llevaría a perder ciclos de reloj para resolver el segundo salto. Hemos de partir del hecho de que el AMD Zen puede procesar hasta 4 instrucciones por ciclo, pues con este cambio la unidad de predicción de saltos podía manejar que al menos dos de sus instrucciones fuesen de salto de manera simultánea, mientras que en los diseños anteriores solo podía con una.
| L0 BTB | L1 BTB | L2 BTB | ITA | |
|---|---|---|---|---|
| Zen | 8 | 256 | 4096 | 512 |
| Zen 2 | 16 | 512 | 7168 | 1024 |
| Zen 3 | 16 | 1024 | 6536 | 1536 |
| Zen 4 | 16 | 1536 | 7168 | 3072 |
| Zen 5* | 16 x 2 | 1536 x 2 | 7168 x2 | 3072 x 2 |
No fue el único cambio introducido por los ingenieros de AMD, lo otro fue utilizar un BTB de tres niveles (L0, L1, L2) y añadir también en llamado Indirect Target Array, el cual se utiliza para las instrucciones de salto indirecto. Es decir, que no contiene la dirección de memoria donde se encuentra el dato y/o la instrucción, sino una dirección de memoria que si que apunta a eso. Tal y cómo se puede ver en la tabla de arriba, con cada nueva generación de la arquitectura, los tamaños de los diferentes niveles del BTB se han aumentado. No obstante, el primer gran cambio se dio con Zen 3 cuando redujeron los ciclos de consulta a la BTB L0 a cero ciclos de espera y en el Zen 5 donde literalmente el FrontEnd se encuentra duplicado.
Jerarquía de caché y Fetch
La siguiente parte importante en el FrontEnd es la captación de datos e instrucciones, una CPU básica lee directamente desde la memoria, sin embargo los microprocesadores actuales utilizan varios niveles de caché a día de hoy y las unidades operan directamente sobre ellos. Es decir, los componentes encargados de procesar la diferentes instrucciones en realidad no tocan jamás la memoria RAM, sino que la información les es traída en bandeja. No obstante, el caso de las arquitecturas AMD Zen es particular, ya que para la comunicación interna del microprocesador inventaron un bus denominado Infinity Fabric, el cual es una versión con coherencia de memoria del HyperTransport.
Controlador de memoria e IOD
El controlador de memoria, el cual se encuentra en el IOD y, por lo tanto, fuera de los núcleos en muchos de los modelos del AMD Ryzen es la parte encargada de leer tanto desde la memoria RAM como del resto de componentes del sistema. Por un lado dispone del Unified Memory Controller, el cual se comunica con la RAM del sistema a la velocidad de reloj del memclk de esta. Dado que en las memorias DDR el memclk es la mitad de su tasa de transferencia, con el bus de 256 bits que tiene puede comunicarse con 2 canales de memoria DIMM de 64 bits cada uno del tipo DDR. No obstante, a partir de Zen 4, con la adopción de la memoria DDR5 y sus particularidades, el UMC parece que esta teniendo problemas.
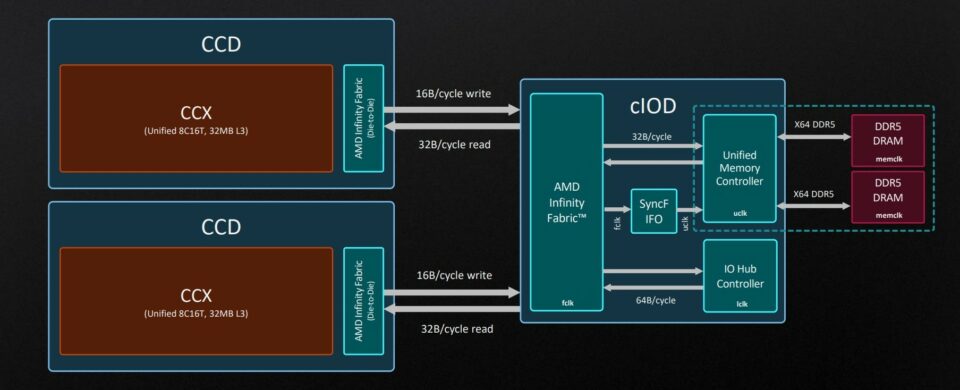
La otra pieza es el IO Hub Controller, la cual tiene un bus de 512 bits, es la encargada de comunicarse con los puertos PCI Express que se encuentran en la misma CPU, asignando normalmente 4 líneas al Southbridge externo para la gestión de periféricos de bajo ancho de banda, 4 líneas para la unidad SSD M.2 y el resto a la tarjeta gráfica. Su velocidad de reloj es mucho más baja que la de la memclk e independiente del memclk de la memoria.
Tanto el UMC como el IO Hub Controller están conectados a lo que en el diagrama es llamado Infinity Fabric, aunque en otras partes la marca lo llama Scalable Data Fabric, se trata de una topología tipo Crossbar a la que los diferentes chiplets (en el caso de estar disgregados los componentes) se conectan. Es escalable por el hecho que su tamaño puede variar dependiendo de la cantidad de chiplets que puede albergar, pudiendo reusar un CCD Chiplet común para diferentes configuraciones, ya sean para servidores o para ordenadores domésticos. Cabe aclarar que los chips para consola y ordenadores portátiles utilizan la misma configuración, pero con todo unificado en un mismo chip.

Cada CCD tiene una conexión directa con el IOD, independientemente de la cantidad de núcleos que albergue en su interior de forma directa, y como hemos dicho lo hará a la memclk de la RAM. Lo cual si bien esto no es un problema en PC con la memoria DDR estándar, si que lo es en consolas ya que la GDDR tiene un memclk 8 veces menor, además de tener una mayor latencia por acceso, provocando que pese a ser Zen 2 su rendimiento por ciclo de reloj caiga a los niveles de la primera generación.
Caché L3 y topologia interna
La caché L3 es compartida por todos los núcleos en cualquier arquitectura Zen, la diferencia es que a partir de la tercera generación la organización general de cada CCD cambio, ya que se paso de cuatro a 0cho núcleos en una misma pieza. Esto llevo a abandonar una topologia del tipo Crossbar a una del tipo anillo, aumentando la latencia entre la L2 y la L3 para cada núcleo, los cuales dejaron de tener acceso directo para tener que esperar su turno a medida que la información circulaba por el anillo central. Dado que la topología es en anillo, la L3 no transfiere 32 B a la caché L2 de cada núcleo en simultaneo, sino que va «rotando» y llena una caché L2 correspondiente en cada ciclo de reloj.No obstante, esto tiene una razón de ser, y es que el tener un Crossbar con tantos núcleos e interconexiones aumentaría el consumo energético hasta la estratosfera, de ahí a que para configuraciones de 6 o más núcleos se usen configuraciones en anillo.
V-Cache
Aprovechando las tecnologías 3DIC de TSMC, AMD creó la llamada V-Cache, la cual es la tecnología clave para las CPU de la gama Ryzen con apellido X3D. La idea no es otra que colocar un chip de memoria SRAM encima de los chiplets CCD que incluyen los núcleos y la memoria caché y conectarlos verticalmente para aumentar la cantidad de caché L3 del sistema. El motivo de hacerlo así es que verticalmente se pueden usar más conexiones para intercomunicar la V-Cache con el CCD y que cada una de ellas vaya a menor frecuencia, reduciendo el voltaje y haciendo que la V-Cache no sobrecaliente al chiplet que tiene debajo.

Hemos de partir del hecho de que el hecho de darle más L3 a la CPU se traduce en que el impacto sobre la RAM principal es menor, en especial en aplicaciones donde hay elementos que han de ser captados frecuentemente por la CPU. Lo que incluye la reproducción de videojuegos. Simplemente el microprocesador con V-Cache puede almacenar una mayor cantidad de los elementos del juego en la memoria caché, reduciendo con ello la latencia al acceder a ellos y con ello el tiempo por instrucción, lo que supone un aumento del IPC en dichas instrucciones.
Sin embargo, la tecnología V-Cache tiene problemas, la primera es que recorta el TDP máximo del chip, lo que hace que sus frecuencias sean más bajas para evitar el ahogamiento termal. La segunda es que la caché L3 en las arquitecturas Ryzen es una Victim Cache, por lo que no se llena desde la RAM, sino con descartes de la L2, por lo que si bien en juegos es ideal, en otras aplicaciones por el retroceso en la frecuencia no es ideal.
Aunque el mayor hándicap es la incapacidad de poderlo usar en más de un CCD, ya que no hay manera de interconectar dos V-Cache en dos chiplets distintos con la suficiente baja latencia.
Cachés privadas (L1 y L2)
En las tres primeras generaciones de los AMD Zen, estos disponen de 512 KB de caché de segundo nivel privada para cada núcleo, esta dispone de un bus paralelo, también de 32 Bytes(256 bits) con el que alimenta de forma simultanea a las cachés L1 de datos e instrucciones, las cuales se encuentran separadas y son de 64 KB para la Instruction Cache y 32 KB para la Data Cache. No obstante, debido a que con la llegada de la DDR5 con Zen 4 el subsistema de memoria de la arquitectura general empezaba a ser un cuello de botella, en AMD decidieron aumentar el tamaño de la caché L2 a 1 MB de tamaño, lo cual demostró no ser suficiente, por lo que decidieron duplicar el ancho de banda entre la L2 y la L1 en Zen 5.
Tanto la caché de datos como la de instrucciones tiene un tamaño de 64 B por línea de cache, al igual que el resto de la jerarquía. Esto es curioso por el hecho que el Infinity Fabric siempre transmite a 32 B por ciclo, por lo que podemos llegar a pensar erróneamente que la CPU requiere 2 ciclos de reloj para llenar una línea de caché, y sí, en realidad es así, pero los microprocesadores actuales cuando ocurren estas cosas no han de esperar ciclos de más. Simplemente, mientras los primeros 32 Bytes (256 bits) de la línea de caché ya se pueden consumir, el resto llega al ciclo de reloj siguiente.
Sin embargo, a partir de Zen 5 la cosa cambia, el ancho de banda entre la L1 y la L2 se duplico. Esto se debe a que la unidad AVX-512 con la que dispone puede operar en un ciclo y requiere ese ancho de datos, por lo que la comunicación L2 a la L1 para instrucciones, así como la comunicación de esta con el doble decodificador.
Decodificación de instrucciones x86
La arquitectura Zen al usar un set de registros e instrucciones x86 ha de tener una serie de decodificadores capaces de leer las instrucciones en dicho formato, en concreto tiene 4 unidades, las cuales toman una línea de caché, de 64 B cada una, y la decodifican en un número variable de ciclos dependiendo la instrucción. Se trata del mayor punto flaco de cualquier microprocesador con dicha ISA, ya que las instrucciones pueden tener un tamaño que vaya desde 1 byte de tamaño a los 16 bytes. El hecho de desglosar y localizar las instrucciones para descomponerlas en micro-operaciones es una tarea titánica.Es más, la complejidad es tal que el decodificador se encuentra dividido en dos etapas, en la primera de ellas se identifica la instrucción y en la segunda se realiza el proceso de decodificación de la misma en varias micro-operaciones.
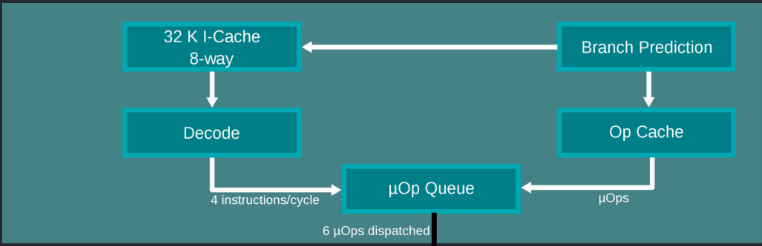
En todo caso hay que aclarar que desde el Pentium Pro que el Backend no trabaja de forma directa con micro-operaciones x86, sino bajo un set de instrucciones propio que es del tipo RISC, por lo que en muchos casos descompone una instrucción compleja en varias más simples. De ahí a que la unidad de Dispatch/Distribución pueda alimentar con 6 micro-operaciones al BackEnd, lo que se traduce en un mayor paralelismo, pese a que las tres instrucciones sean de entrada. Claro está que no podemos olvidar que la decodificación de instrucciones x86 es una tarea titánica, de ahí el enorme tamaño de los decodificadores tanto en los chops de AMD como el de Intel.
Micro-Op Cache
Si bien la primera CPU en tener una caché de micro-operaciones fue el Sandy Bridge de Intel, su utilidad es tal que se ha implementado en CPU posteriores. Su utilidad de cara a añadir rendimiento es clara, almacena las instrucciones ya decodificadas para ahorrar todo el proceso y alimenta de forma directa al Backend. Tan pronto como una nueva instrucción entra desde la caché de instrucciones se comprueba que se encuentre en el índice de la Micro-Op Cache y se hace el bypass para enviarlo directamente a la cola de micro-operaciones, la cual es manejada por la unidad de Dispatch.
| Cola de instrucciones | MicroOp Cache | MicroOp Queue | |
|---|---|---|---|
| Zen | 20 x 16 Bytes | 2048 | 72 |
| Zen 2 | 20 x 16 Bytes | 4096 | 72 |
| Zen 3 | 24 x 16 Bytes | 4096 | 72 |
| Zen 4 | 24 x 16 Bytes | 6912 | 72 |
Eso sí, hemos de aclarar que la primera CPU en tener una caché de micro-operaciones no fue el AMD Zen de 2017, sino el Sandy Bridge de Intel lanzado en 2011, eso sí, con menor capacidad. Por otro lado, no hemos de confundir la cantidad de instrucciones que se recoge el decodificador de la cantidad que se pueden enviar a las unidades de ejecución de la CPU, ya que si bien el decodificador tiene un limite en cuanto a la cantidad de instrucciones por ciclo, cada una de ellas se puede traducir en varias micro-operaciones que de haber unidades de ejecución disponibles se pueden resolver en paralelo. Además, el hecho de tener una caché de micro-operaciones permite almacenar las instrucciones previamente decodificadas, lo que significa ahorrarle trabajo el decodificador y aumentar la cantidad de instrucciones que se envían al Backend.
El caso de Zen 5
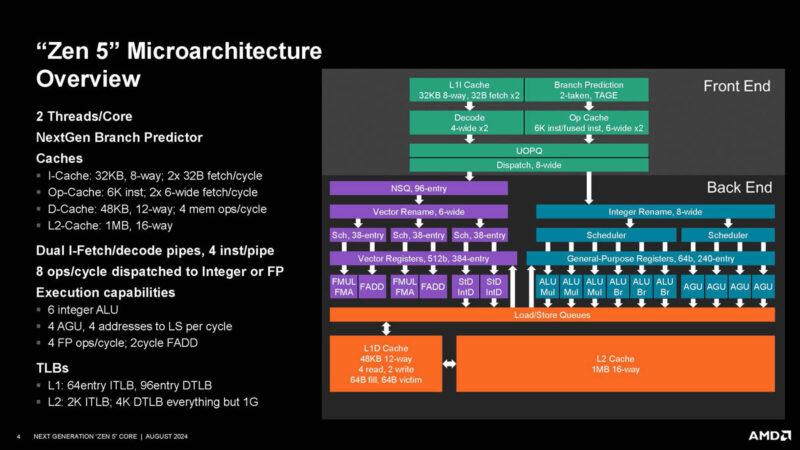
Después de cuatro generaciones en la arquitectura, AMD decidió renovar por completo el Frontend de su arquitectura en Zen 5, siendo este el cambio más drástico en la arquitectura desde el lanzamiento original de 2017. Dado que se paso de un solo decodificador capaz de entregar 6 micro-operaciones al Backend a tener dos decodificadores en paralelo, con la capacidad de transmitir 4 micro-operaciones cada uno de ellos. Esto trajo otros cambios, como el hecho de que la caché L1 contiene ahora un doble bus para alimentar tanto un decodificador como otro. ¿El único hándicap? Si el multihilo (SMT) se encuentra activo, entonces cada hilo de ejecución obtiene uno de los dos decodificadores.
Ejecución fuera de orden
Desde la sexta generación de las CPU de Intel (Pentium Pro/Pentium II/Pentium III) la ejecución de los programas es en fuera de orden, es decir, que las instrucciones no se resuelven en el orden del programa, sino a medida que las unidades de ejecución se encuentran disponibles. Esto reduce enormemente las paradas que se producían cuando una instrucción se encontraba a la espera en solucionarse y terminaba atrasando todas las demás. Si bien esta estrategia no se puede usar para todo el programa, su implementación a mediados de los 90 fue suficiente como para que los x86 le dieran la vuelta a la tortilla y superasen a los RISC. Eso y la decodificación en micro-operaciones que hacen que todo microprocesador internamente funcione como un RISC, rompiendo la ventaja de estos últimos.
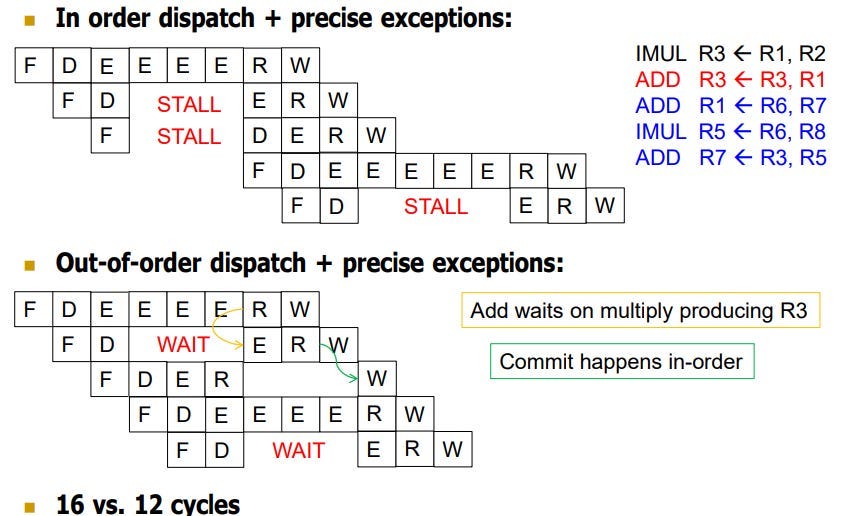
Es por ello que se añaden una serie de planificadores, los cuales se encargan de organizarle la agenda a las diferentes instrucciones e indicarles cuando hay un hueco libre para poderse ejecutar. Eso sí, las instrucciones se ejecutan de forma ordenada según su tipo de instrucción y de los recursos disponibles. Es aquí donde se ve la importancia de una buena predicción de saltos, ya que independientemente de que se pueda desordenar la ejecución de las instrucciones según su disponibilidad, un mal salto puede llevar al traste todo el rendimiento de la CPU. A día de hoy todos los microprocesadores que usamos son fuera de orden, incluidas las consolas chinas de emulación que nos cuestan menos de 50 €.
El algoritmo de Tomasulo
Estos dos componentes se encuentran en todas las CPU fuera de orden y son esenciales para evitar conflictos a la hora de ejecutar instrucciones y hacerlo de la forma correcta. Dentro del pipeline de cualquier CPU se encuentran en el espacio situado entre el FrontEnd y el BackEnd, relacionados justo con la unidad de Dispatch, encargada de enviar las instrucciones a procesar a las diferentes unidades del BackEnd. A esto se le llama organización de Tomasulo, cuyo nombre se lo debemos a Robert Tomasulo quien lo invento para el IBM/360 en la década de los 60, pero no se implemento en los microprocesadores de PC hasta el Pentium Pro.
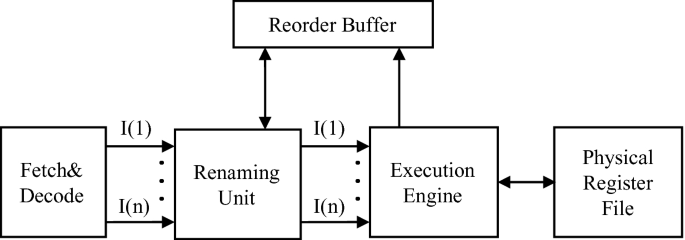
En las CPUs que implementan ejecución fuera de orden estilo Tomasulo, normalmente encontramos tres componentes principales trabajando juntos. El primero de los componentes son las llamadas estaciones de reserva, cada tipo de unidad de ejecución tiene su propia estación de reserva. Su trabajo es sencillo, esperan los operandos de las instrucciones aritméticas mientras que al mismo tiempo controlan la ejecución fuera de orden, por lo que se trata de una serie de registros especiales que entre otras cosas almacenan:
- La operación a realizar.
- Operandos listos o referencias a los resultados pendientes (etiquetas de otras RS o registros físicos).
Tan pronto como los operandos están listos se encuentran en la estación de reserva correspondiente entonces la unidad de ejecución los procesa de forma directa sin tenerlos que ir a buscarlos siquiera a la memoria caché.
ReOrder Buffer y Register Renaming
Sin embargo, el algoritmo de Tomasulo requiere dos unidades adicionales que son esenciales para su correcto funcionamiento, el primero de ellos es el Reorder Buffer o ROB. Y es que hemos de partir del hecho que la ejecución fuera de orden puede producir resultados listos antes que instrucciones anteriores. Es más, si se da un caso de fallo o excepción, entonces que el microprocesador se ponga a escribir resultados de forma inmediata puede llegar a corromper el programa final.
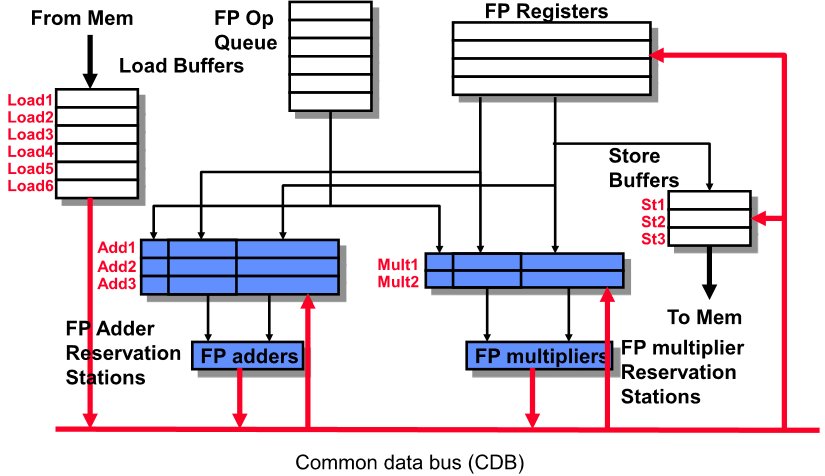
La solución a ello es el ReOrder Buffer, donde:
- Cada instrucción tiene un entrada en el ROB cuando se decodifica.
- Los resultados de ejecución se escriben temporalmente en el ROB, no directamente sobre los registros de salida.
- Solo cuando ya se tienen todas las instrucciones en el orden inicial del programa es cuando se escriben en los registros correspondientes.
Como socio del ROB tenemos a lo que llamamos renombramiento de registros, sin este las diferentes instrucciones podrían usar un mismo registro a la hora de escribirse al completarse la instrucción, la idea aquí es simple, aunque puede parecer contraintuitivo. Cada una de las instrucciones tiene asignado un registro físico siempre libre como destino, con ello las instrucciones que leen dicho registro saben el registro físico del cual han de captar el dato para procesar. Es decir, en vez de tener un registro genera que pueden necesitar varias instrucciones, lo que hacemos es que cada resultado se almacene en una memoria intermedia propia y no se vea desplazado antes de escribirlo en los registros estándar
Planificadores
En los núcleos de las CPU modernas, un planificador contiene una cola o lista de espera para aquellas instrucciones ya decodificadas y renombradas, pero que aún no se pueden ejecutar. El trabajo de los planificadores es asignar las instrucciones a las diferentes unidades de ejecución una vez sus operandos ya se encuentran listos. Por lo que son como controladores de tráfico, ya que deciden qué instrucción entra a qué unidad funcional y cuándo, evitando cuellos de botella y asegurando que todo fluya eficientemente.
La forma de relacionarse entre los planificadores, los ROB y el renombramiento de registros ocurre de la siguiente manera:
-
La instrucción entra a la estación de reserva después de decodificarse y renombrarse.
-
El planificador lee la información en la estación de reserva:
-
Si los operandos están listos, la instrucción se envía a la unidad funcional correspondiente.
-
Si no, espera hasta que llegue el dato por el CDB.
-
-
El resultado se envía al ROB para ser enviado a los registros en el orden original del programa, manteniendo coherencia del programa.
| Concepto/Zen | Zen 1 | Zen 2 | Zen 3 | Zen 4 | Zen 5 |
|---|---|---|---|---|---|
| Entradas ROB | 192 | 224 | 256 | 320 | 448 |
| Ancho rename entero | 4 | 4 | - | - | 8 |
| Ancho rename FP | 6 | 6 (caminos FP duplicados) | - | - | 6 |
| Planificadores enteros | 4 × 14 entradas | 4 × 16 entradas | 4 × 24 entradas (Int+AGU) | - | - |
| Planificadores AGU | 2 × 14 entradas | 1 × 28 entradas | - | - | - |
| Planificadores FP | Cola de 96 entradas | 36 entradas en scheduler + 64 entradas no planificadas | 64 + 2×32 entradas | - | 3 × 32 entradas en scheduler + 96 entradas no planificadas |
| Archivo de registros enteros | 168 | 180 | 192 | 224 | 240 (64-bit) |
| Archivo de registros FP | 160 | 64 + 36 | - | 192×512-bit | 384 (512-bit) |
| Otros | - | - | - | Archivo de máscaras AVX512 de 68 entradas | - |
En el caso de las arquitecturas AMD Zen tenemos tres planificadores distintos funcionando
-
Planificador entero (Integer scheduler):
-
Maneja instrucciones aritméticas y lógicas enteras.
-
Decide cuándo enviar la instrucción a la ALU correspondiente.
-
-
Planificador AGU (Address Generation Unit):
-
Maneja instrucciones de cálculo de direcciones para memoria (LOAD/STORE).
-
Conecta con la memoria y coordina los accesos.
-
-
Planificador de punto flotante (FP scheduler):
-
Maneja operaciones de punto flotante y vectores (SSE, AVX, AVX512).
-
Coordina las unidades FPU y los registros FP renombrados.
-
Con ello llegamos a la parte final de lo que es el FrontEnd de la CPU y de paso hemos explicado como funciona la ejecución fuera de orden, no obstante, ahora nos toca relatar la parte encargada de ejecutar las diferentes instrucciones, lo que es conocido como el Backend de la CPU o también como unidad de ejecución cuyo trabajo es resolverlas y devolver un resultado para cada una de ellas.
Backend de la CPU
Cuando una unidad de ejecución queda libre esta ha de seguir un camino, pensad en cada instrucción como un pasajero en un aeropuerto esperando a tomar su avión. En el caso de las arquitecturas AMD Zen ya hemos visto como tenemos tres terminales distintas, una para enteros, otra para operaciones a memoria y una última para coma flotante y operaciones vectoriales. Pues bien, la unidad de Dispatch se encargará de llevar a las diferentes instrucciones a su destino final, las cuales se encuentran conectadas cada una a un Execution Port. Es más, se ha de aclarar que una misma arquitectura puede evolucionar a tener cada vez más una mayor cantidad de unidades de ejecución, lo cual no significa que las utilice al mismo tiempo.
Por lo que si bien no es habitual evolucionar el FrontEnd de una CPU hasta muchos años después, no ocurre lo mismo con el BackEnd y un ejemplo de ello es la evolución que han tenido las diferentes generaciones del AMD Zen desde la primera hasta la actual quinta generación.
Unidades y puertos de ejecución
En una CPU fuera de orden, lo importante es que la siguiente instrucción tenga una unidad disponible para poderse ejecutar con la mayor celeridad posible, es por ello que con cada nueva iteración de la arquitectura Zen la cantidad de puertos ha ido aumentando progresivamente, añadiendo nuevas unidades y mayor cantidad de las ya existentes. ¿Las consecuencias? Un aumento considerable de la cantidad de instrucciones solventadas o retiradas por ciclo de reloj.
El Backend se divide en dos partes distintas trabajando en paralelo, por un lado la parte de enteros y de operaciones con la memoria, por el otro lado parte que engloba coma flotante y vectorial. En el modelo inicial del AMD Zen, la cantidad de puertos de ejecución disponibles era de diez, divididos de la siguiente forma:
- 4 ALU de enteros y 2 AGU utilizadas para el cálculo de direcciones de memoria.
- 2 Unidades FMUL/FMA en el pipeline de coma flotante y 2 unidades FADD, cada una de ellas capaz de trabajar bajo una precisión de 128 bits para las instrucciones AVX/Vectoriales.
- 1 unidad Load/Carga
- 1 Unidad Load/Almacenamiento.
Hay que entender que las unidades AVX y las de coma flotante escalar están conmutadas en los mismos puertos, esto se hace por el hecho que las instrucciones SIMD no son lo suficientemente comunes en los programas como para asegurarles un puerto propio.
Zen 2
- Se añadió una AGU adicional en el pipeline de enteros, por lo que la cantidad de puertos de ejecución pasa a ser 11.
- Ahora soporta 256 bits por ciclo para las instrucciones AVX, permitiendo resolverlas en la mitad de tiempo respecto al Zen de primera generación.
- La variante de PS5 del Zen 2 carece de las dos unidades FADD en este caso.
Zen 3
El Backend se amplió enormemente pasando de los 11 a los 14 puertos, sin embargo, oficialmente solo se ocuparon dos de ellos:
- En el pipeline de enteros se añade una Branch Execution Unit, no confundir con la Branch Prediction Unit. En este caso se encarga únicamente de gestionar y ejecutar las instrucciones de salto, no de predecirlas. Por lo que es una forma de liberarlas del trabajo a la hora de gestionarlas.
- Ahora tenemos una unidad de almacenamiento/store adicional.
Zen 4
Mantuvo la configuración de 14 puertos de ejecución, asignándole el puerto faltante a una segunda unidad AVX, la cual en combinación con la primera permite ejecutar instrucciones AVX-512. Por lo que los cambios en esta generación fueron más bien pocos, lo cual es uno de los motivos por los cuales su salto en rendimiento no fue tan alto como en otras generaciones.
Zen 5
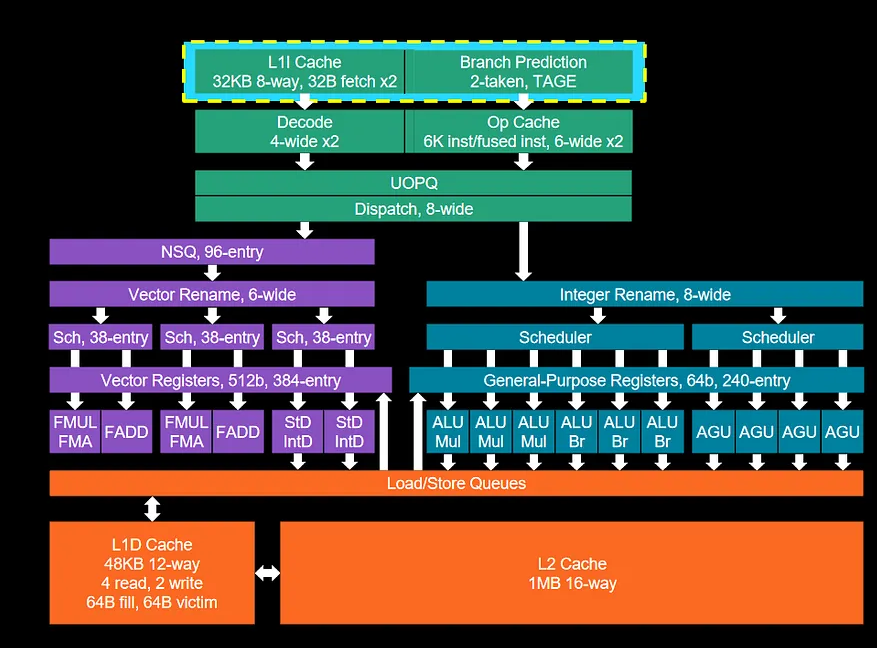
En este caso la cantidad de puertos de ejecución ha aumentado de 14 a 16, pero con matices, dado que el cambio es mucho más profundo en la arquitectura que en versiones anteriores.
- Las dos unidades AVX de 256 bits se ha visto reemplazadas por una unidad única de 512 bits, liberando uno de los puertos en el proceso.
- El pipeline de enteros ahora tiene 6 ALU para enteros y 4 AGU.
- Las unidades FMUL/FMADD y FADD ya no están separadas, sino conmutadas bajo un mismo puerto por cada conjunto. Lo que se traduce en que quedan dos puertos libres, pero también un margen de mejora en posteriores versiones con mayores puertos de ejecución.
- Las unidades StD/IntD son las unidades Load/Store, no tienen más secreto.
Load/Store
Las unidades Load/Store se encargan de ejecutar las instrucciones relacionadas con la memoria, por lo que serán las que realizaran peticiones a la memoria caché y se encargaran de actualizar los registros. Inicialmente, las CPU de tipo CISC no tenían este tipo de unidades, pero si las RISC, ya que una parte esencial de toda instrucción es la parte encargada de acceder a memoria y dado que esto era una parte común se creo dos nuevos tipos de unidades de ejecución nuevas, lo que al mismo tiempo permitió descomponer aún más las instrucciones. Su funcionalidad es la siguiente:
- Load (cargar): Trae datos desde la memoria principal (RAM) hacia un registro de la CPU, no obstante, lo primero que hará será buscar la información en la memoria caché.
- Store (almacenar): Envía datos desde un registro de la CPU hacia la memoria principal. Si la dirección de memoria a la que apunta a donde se ha de almacenar se encuentra en la caché, actualizará las líneas correspondientes.
El gran cambio se dio con el Pentium Pro, que fue el primer microprocesador de la familia x86 en implementar este tipo de unidades clásicas de los microprocesadores RISC por primera vez, tomándole el relevo el clásico AMD Athlon a la hora de adoptarlas.. Dichas unidades por lo tanto no se encontraban en las CPU clásicas y de ahí que las estemos explicando ahora, ya que fueron inéditas en PC hasta bien entrados los años 90.
LS en AMD Zen
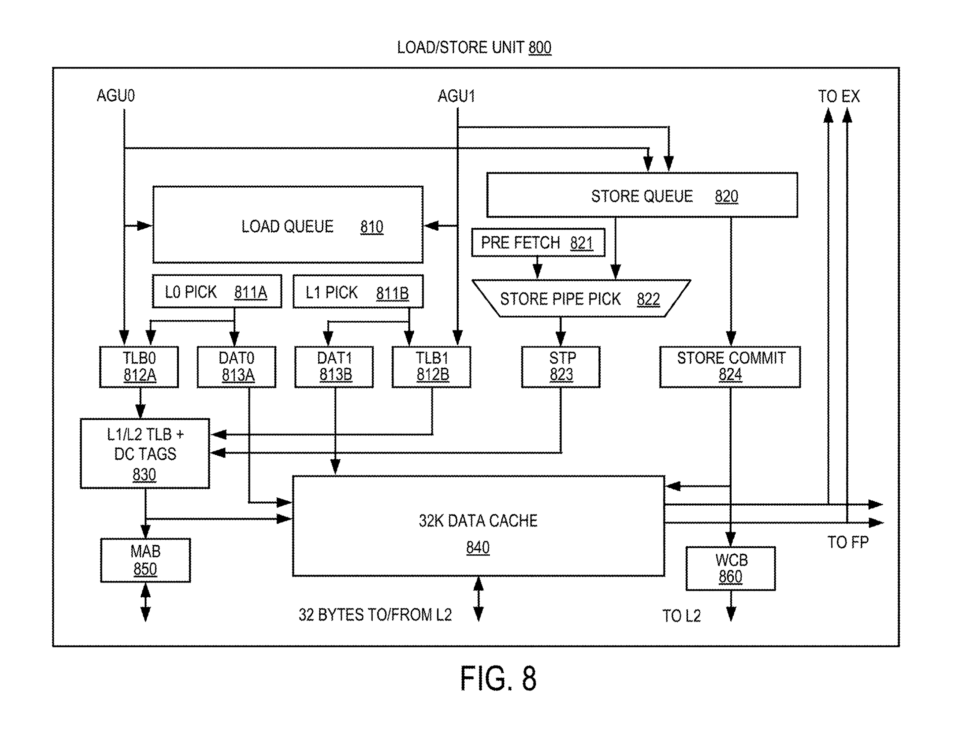
En las diferentes generaciones de los núcleos Zen tenemos diferentes unidades Load/Store, las cuales interactúan con la caché de datos de primer nivel y luego con la caché de segundo nivel que almacena tanto datos como instrucciones a nivel local. La evolución en este caso ha ido de la siguiente manera:
- El Zen de primera generación puede realizar dos cargas de 16 Bytes cada una desde la caché 1 almacenamiento de 32 bytes por ciclo de reloj. Su búfer de carga, el cual almacena temporalmente las siguientes peticiones es de 72 entradas, mientras que el de almacenamiento es menor con 44 entradas.
- Zen 2 en cambio, aumenta el ancho de banda de las cargas a 32 bytes, la cola de almacenamiento ha aumentado a las 48 entradas.
- Para Zen 3, la cola de almacenamiento ha aumentado a las 64 entradas, mientras que la carga hasta las 116. Al mismo tiempo ha aumentado también el ancho de banda, permitiendo almacenar 3 cargas de 32 bytes cada una para y 2 almacenamientos del mismo tamaño.
- Zen 4 no evoluciono respecto a Zen 3 en este aspecto.
- Ya para terminar, con Zen 5 se añadió a que la unidad de almacenamiento pueda almacenar 64B (512 bits en un solo ciclo, haciendo posible las instrucciones AVX-512) en un solo ciclo, en vez de dos como ocurría en la cuarta generación.
Memoria caché en AMD Zen
Las unidades Load/Store son las encargadas de escribir los datos desde los registros a la caché de primer nivel de datos una vez se ha terminado la instrucción. Cada uno de los núcleos Zen dispone de dos niveles de memoria caché, el primero de ellos al igual que en el resto de las CPU se encuentra dividido en dos mitades, una para datos y la otra instrucciones. Mientras que la de segundo nivel es generalista y engloba los dos tipos de datos.
- La cache de datos de primer nivel es de 32 KB por núcleo, será está con la que interactuaran las unidades Load/Store, mientras que la caché L2 es de 512 KB por núcleo.
- A partir de Zen 4 la caché L2 vio incrementado su tamaño a 1 MB.
- En Zen 5 la caché L1 de datos se ha aumentado un 50% tanto en velocidad como en tamaño (48 KB), además también se ha duplicado el ancho de banda con la L2.
No obstante, existe un tercer nivel de caché fuera de los núcleos, la llamada L3, la cual almacena las líneas de caché descartadas por parte de la L2. Esto significa que a la hora de acceder a memoria la L3 es tratada como una extensión de la L2 realmente y al mismo tiempo, las unidades de precaptación de datos e instrucciones la ignoran por completo. a razón principal es que el prefetch no está atendiendo una falla real de caché (cache miss), sino que está especulativamente trayendo datos que podrían ser útiles.
Fin del camino
Antes de nada, perdonadnos, pero se publicó un borrador incompleto y sin revisar de reportaje del que faltaba mucha información, por lo que si estáis leyendo esto os encontráis ante la versión corregida.