Dado que las NVIDIA RTX 50 ya se encuentran en el mercado, hemos decidido hacer un sencillo reportaje sobre las novedades de su arquitectura y cambios que consideremos más destacados. No se trata de una comparativa técnica y tampoco encontraréis benchmarks, pero sí una explicación a las nuevas tecnologías implementadas y su utilidad en actuales y futuros títulos en el mundo de los videojuegos para PC.
Los modelos de las RTX 50
A continuación os dejamos, de manera resumida, la configuración de las diferentes tarjetas gráficas de la gama NVIDIA RTX 50 lanzadas hasta el momento de escribir este artículo, incluiremos los modelos que faltan a medida que sean anunciados por la propia NVIDIA.
| Modelo | SM (Núcleos de GPU) | Frecuencia (Base/Boost) | Memoria | Ancho de Banda | Consumo Energético (TGP) |
|---|---|---|---|---|---|
| RTX 5090 | 170 | 2,01 GHz / 2,41 GHz | 32 GB GDDR7 | 1.792 GB/s | 575 W |
| RTX 4090 | 128 | 2,23 GHz / 2,52 GHz | 24 GB GDDR6X | 1.008 GB/s | 450 W |
| RTX 5080 | 84 | 2,30 GHz / 2,62 GHz | 16 GB GDDR7 | 960 GB/s | 360 W |
| RTX 4080 | 76 | 2,21 GHz / 2,51 GHz | 16 GB GDDR6X | 736 GB/s | 320 W |
| RTX 5070 Ti | 70 | 2,30 GHz / 2,45 GHz | 16 GB GDDR7 | 896 GB/s | 300 W |
| RTX 4070 Ti | 60 | 2,31 GHz / 2,61 GHz | 12 GB GDDR6X | 504 GB/s | 285 W |
| RTX 5070 | 48 | 2,16 GHz / 2,51 GHz | 12 GB GDDR7 | 672 GB/s | 250 W |
| RTX 4070 | 46 | 1,92 GHz / 2,48 GHz | 12 GB GDDR6X | 504 GB/s | 200 W |
Además, los hemos comparado con las RTX 40 para que seáis conscientes del salto generacional y por si a alguno de vosotros le interesa dar el salto desde la última generación, lo cual no recomendamos para el usuario medio.
Memoria GDDR7
Una de las puntas de lanza de las RTX 50 de NVIDIA es el hecho de que se trata de la primera GPU en utilizar memoria GDDR7, la cual tiene un ancho de banda que en algunos casos llega a duplicar la GDDR6. Por desgracia, la cantidad de memoria disponible no ha aumentado respecto a la anterior generación, excepto por el aumento del ancho del bus (de 384 bits a 512 bits en la RTX 5090), ya que la capacidad de cada chip sigue siendo de 2 GB, lo que no quita la aparición de futuros modelos con el mismo ancho del bus, pero con una mayor cantidad de VRAM.

Esto es decepcionante en los modelos con buses más estrechos, y es que llevamos estancados en las mismas cantidades de memoria desde las RTX 30, las cuales fueron lanzadas allá por el año 2020, es decir, algo más de cuatro años. En todo caso, el mayor ancho de banda de la GDDR7 en las RTX 50 se traduce en que en la mayoría de casos ni la 5090 puede sacar el provecho de su enorme ancho de banda, pero este situación es normal cuando se adopta un nuevo tipo de VRAM. Simple y llanamente, os tenéis que quedar con que es muy rápida y que no ocasiona un cuello de botella para la mayoría de aplicaciones.
No obstante, hay una aplicación donde el ancho de banda de la GDDR7 toma ventaja y esta es la realidad virtual, donde se requieren no solo renderizar frames a gran velocidad y lo más rápido posible, sino también altas tasas de refresco, lo que conlleva una presión sobre la VRAM mucho mayor.
Los núcleos de las GPU RTX 50 (Blackwell)
NVIDIA ha aumentado la cantidad de las ALU de enteros (INT32) en cada SM de 64 en total a 128, igualando el número de unidades FP32 que ya eran 128 en las RTX 30 y RTX 40. Obviamente, dichas unidades no calculan en coma flotante, FLOPS, por lo que no suman en la suma total de «potencia» que se suele usar erróneamente para medir la capacidad de trabajo de una GPU.

Al igual que en arquitecturas anteriores, tenemos en cada SM 4 subcore idénticos, y como se puede ver en el gráfico de arriba, ha habido un cambio importante. Ahora bien, el aumento de las unidades de enteros de 32 bits no es algo banal, ya que este tipo de unidades se utilizan en varios elementos importantes:
- Las unidades INT32 se utilizan para cosas como el manejo de coordenadas de píxeles, índices de vértices y cálculos de texturas.
- Si ya hablamos de lógica de programa, las operaciones INT32 se utilizan para manejar índices de matrices, bucles y condiciones lógicas.
- Son útiles para operaciones de precisión discreta, como decisiones condicionales y cálculos de control.
- En los Shaders no orientados a gráficos, las unidades INT32 se utilizan para algoritmos que requieren manipulación de enteros, como algoritmos de búsqueda, clasificación y procesamiento de datos.
No obstante, al contrario de lo que ocurre en las CPU, donde las unidades de enteros y coma flotante funcionan en paralelo, aquí se encuentran conmutadas, por lo que solo podemos acceder a una unidad SIMT de 32 ALU INT32 y su hermana FP32 al mismo tiempo dentro del mismo subcore. Por lo que en cada subcore, aun cuando hay una instrucción INT32 lista, debe esperar si la ALU está ocupada con una FP32, introduciendo burbujas en el pipeline donde las instrucciones están a la espera.
¿A qué se debe realmente este cambio?
En las GPU con arquitectura GeForce Ampere (RTX 40), cada warp (32 hilos) se dividía en 16 hilos para poderse ejecutar en las configuraciones SIMT de 16 ALU de tamaño, esto hacía que se necesitaran 2 ciclos para completar una ola. La diferencia ahora es que se pueden enviar los 32 elementos de una ola de golpe, pero han de ser en coma flotante o enteros. Es decir, pese a que una configuración SIMT al contrario de una SIMD nos permite darle trabajo a las ALU sobrantes en ciertas circunstancias, todas ellas han de operar en enteros o bajo coma flotante.

En realidad, y esto es algo que el marketing de NVIDIA nunca dirá, la última gran arquitectura hecha desde cero desde sus laboratorios fue Volta, pero los cambios de nombres en cada nueva generación nos han hecho pensar que ha habido una nueva arquitectura con cada nueva generación al completo, cuando realmente lo que hemos ido viendo son cambios graduales y mejoras. Lo que no se ha tocado de una generación a otra sigue estando igual, y es que estamos hablando de monstruos de decenas de miles de millones de transistores.
Tanto es así, que al contrario de lo que ocurre con AMD, donde están continuamente tocando la ISA de la GPU de una generación a otra, en NVIDIA solo han creado 3 sets de instrucciones desde cero en tres ocasiones. G80 (GeForce 8800), Fermi (GeForce 400) y Volta, cuya ISA sigue vigente a día de hoy y se ha utilizado en todas las NVIDIA RTX hasta el momento.
Shader Execution Reordering 2.0
Esta funcionalidad ya se encontraba en las RTX 40 (Ada), pero NVIDIA la ha mejorado en las RTX 50 (Blackwell) y consiste en reagrupar las instrucciones según el tipo de shader y de dato, lo que evita las llamadas burbujas que ocurren cuando hay instrucciones esperando a ser procesadas y no hay unidades disponibles. La idea no deja de ser la misma que la ejecución fuera de orden, pero optimizada para las GPU.

No obstante, no se trata de una funcionalidad disponible a nivel de hardware, sino que se trata de un programa ejecutado a través de una API el encargado de realizar el reordenamiento de las instrucciones en diferentes olas. Es decir, se trata de un shader de propósito general o de computación el encargado de usar los núcleos libres de la GPU para el reordenamiento. El objetivo no es conseguir un mayor rendimiento, sino conseguir el mismo rendimiento, pero utilizando menos núcleos para el mismo proceso.
Neural Shaders: la killer app de las RTX 50
Ahora bien, hemos dejado a los Tensor Cores de lado, esto se debe a que normalmente en las generaciones anteriores a la RTX 50, las unidades de enteros y coma flotante al compartir los registros con las unidades tensoriales, esto provocaba que estos últimos estuvieran en desuso excepto en momentos puntuales. No olvidemos que cualquier tipo de ALU necesita sus registros para operar; si estos se encuentran ocupados, entonces no pueden hacer nada.

Pues bien, NVIDIA, en vez de permitir que las unidades de enteros y coma flotante convencionales no tengan que compartir registros, lo que lleva a que estén conmutadas, le ha dado preferencia a que los Tensor Cores no lo estén respecto al resto de unidades en el núcleo de la GPU. Es decir, ahora a la hora de crear shaders de cualquier tipo se podrán utilizar dichas unidades, de ahí lo de Neural Shaders. Este es el principal cambio que han hecho los de Jen Hsen Huang en la arquitectura de sus RTX 50 (Blackwell) y que supondrá programas shader exclusivos, ya sean para gráficos o computación pura, dado que a ninguna GPU de AMD y de Intel en el mercado, tiene esta particularidad.
DLSS 4 y el Multiframe Generation
Con el lanzamiento de las RTX 40 vimos por primera vez el DLSS3 y el Frame Generation, el cual consiste en la creación de fotogramas intermedios utilizando técnicas de Deep Learning tomando la información de otros dos ya creados.
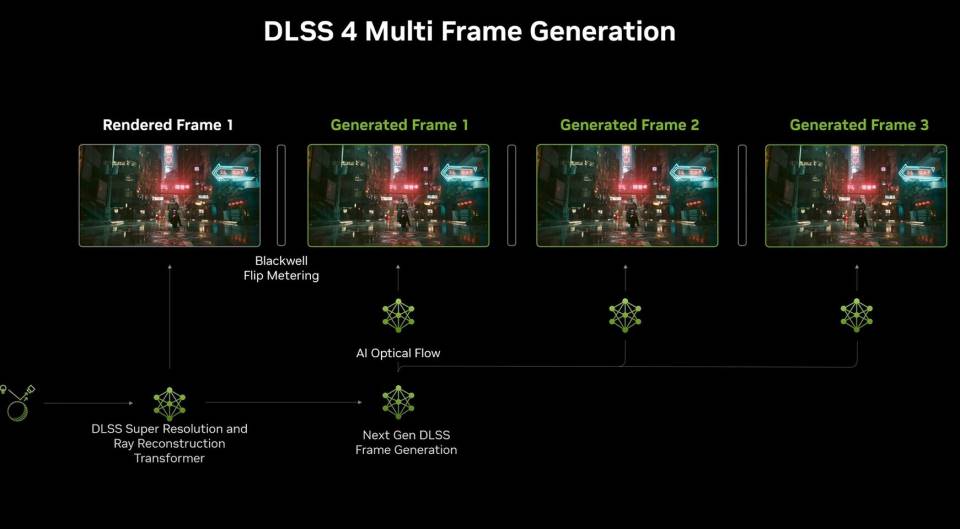
El DLSS 4 trae consigo la extrapolación de frames, la cual consiste en la creación de fotogramas consecutivos a los ya existentes, por lo que la extrapolación busca «adivinar» qué frames seguirían después del último frame disponible. Esto se consigue a partir de conocer las trayectorias de movimiento de los diferentes objetos en la escena, conociendo para ello la velocidad de cada uno.

Sin embargo, fuera de ser una forma algo tramposa de conseguir altas tasas de frames por segundo, su precisión a la hora de reconstruir los frames intermedios deja mucho que desear y si encima con la extrapolación, la cosa se complica, ya que no tenemos la referencia de los fotogramas reales en los dos extremos. Pensad que los frames via IA no se basan en crear una lista de pantalla y recalcular la geometría, es más sencillo que eso y lleva a errores visuales graves.
Mejoras en el algoritmo de superresolución del DLSS
No obstante, el mayor cambio en las RTX 50 no está en la creación de frames automáticos, sino en el algoritmo de superresolución, al pasar de una red neural convolucional (CNN) a usar transformadores. En la anterior versión del DLSS, se analizaban las partes más pequeñas de la imagen y se iba aumentando la complejidad a medida que se iban añadiendo más capas, haciendo que fueran eficaces a la hora de detectar patrones locales en la imagen.

El uso de transformadores en el DLSS 4, al no limitarse a los patrones locales y tener un mecanismo de autoatención, le permite identificar los patrones más globales de cada frame. Es decir, puede detectar las relaciones y detalles no solo entre los píxeles cercanos entre sí, sino también los más complejos. Esto permite captar detalles más complejos y a gran escala, que la versión anterior no podía ver. Al igual que en las versiones anteriores del DLSS, el algoritmo de superresolución sigue tomando información de los fotogramas anteriores, solo que ahora ve mejor y más detalles, lo que recortará la aparición de artefactos gráficos y errores en la reconstrucción vía Deep Learning del frame a más resolución.
No obstante, lo malo es que esto supone un aumento en los costes computacionales del DLSS, los cuales se multiplican por 4 respecto al modelo anterior, por lo que es muy probable que en un tiempo determinado os encontréis que las gamas de las RTX más veteranas se queden sin poder ejecutar dicho algoritmo en los juegos. Lo cual no deja de ser una especie de obsolescencia programada por parte de NVIDIA.
El nuevo RT Core
No es ningún secreto que NVIDIA siempre va una generación por adelantado de AMD y el caso de las RTX 50 (Blackwell) no podía ser distinto, en este caso las mejoras vienen de cara a mejorar el uso de los RT Cores de cara al Ray Tracing en escenas con una densidad geométrica muy alta, ya sea por el uso de Nanite en Unreal Engine 5 o por crear el uso de geometría muy compleja a través de los Mesh Shaders.

Una de las ventajas que tiene AMD respecto a NVIDIA es el Geometry Processor/Geometry Engine, que puede eliminar la geometría superflua y fuera del alcance de la cámara en cada frame. Puede hacerlo de media al doble de velocidad que lo que tardan las unidades de rasterizado (función fija) a convertir triángulos en píxeles. Sin embargo, con Nanite y los Mesh Shaders se puede crear geometría muy pequeña, dentro del campo visible, pero que no sería visible a la cámara, lo que provoca un aumento considerable de la cantidad de intersecciones a calcular. ¿Las consecuencias de ello? Una caída enorme en el rendimiento en escenas con una geometría muy densa, lo que requiere optimizaciones en la unidad de intersección.
RTX Mega Geometry
Una de las mayores ventajas del Unreal Engine 5 es permitir cantidades ingentes de geometría en pantalla. ¿El problema con el Ray Tracing? Que la forma de construir el árbol BVH hasta el momento era de acuerdo al renderizado clásico de la geometría, es decir, al existente previamente a la creación de los Mesh Shaders. Si bien las GPU RTX 50 (Blackwell) soportan sin problemas los métodos antiguos, el nuevo RT Core está pensado para aprovechar con una alta densidad geométrica que permiten las tecnologías como Nanite y los Mesh Shaders.


Los Mesh Shaders son un sustituto de todos los shaders utilizados para el procesamiento de la geometría de la escena, al contrario que los Vertex Shaders tienen la capacidad de crear geometría de la nada, al contrario que los clásicos Vertex shader que son solo capaces de cargar desde memoria una cantidad exacta y no tienen la capacidad de crear diferentes topologías. Para que os hagáis una idea, podemos modelar la geometría como queramos de forma procedural, añadiendo o quitando valores. ¿La única limitación? La cantidad de elementos que pueden ejecutar los shaders en paralelo.
En cuanto a Nanite en el Unreal Engine 5, al igual que los Mesh Shaders, este trabaja con pequeños grupos de triángulos (llamados clústeres) de manera incremental. La idea es que cada uno de estos clústeres se procesa dentro de cada SM o núcleo de la GPU. Además, su configuración puede cambiar de forma dinámica de un frame a otro, lo que permite destruir o generar geometría según el nivel de distancia del objeto respecto a la cámara.
Una nueva forma de construir el árbol BVH
Dicho aumento considerable de la densidad geométrica provoca que el número de intersecciones a realizar por los RT Cores aumente. No hemos de olvidar que se trata de una unidad de función fija donde la cantidad de cálculos que puede hacer por ciclo es limitada. El hecho de verse sobrepasadas afecta al rendimiento general de la GPU de cara al Ray Tracing, por lo que para las RTX 50 (Blackwell) NVIDIA ha decidido cambiar la forma en la que se genera y se recorre el árbol BVH.

La idea es simple, en vez de construir el BVH tomando como referencia los triángulos individuales de los objetos, crea estructuras de aceleración llamadas CLAS (Cluster-level Acceleration Structures) que bajo Nanite en Unreal Engine 5 pueden estar compuestos por hasta 256 triángulos. Estos CLAS se generan bajo demanda (cuando un objeto se carga en la memoria, por ejemplo) y se pueden almacenar para ser reutilizados en los cuadros futuros, ya sea en la memoria o incluso en el SSD, gracias a las capacidades de virtualización de la geometría de tecnologías como Nanite.
Gracias a ello, el proceso necesario para construir el BVH en cada frame se reduce drásticamente, ya que este, en vez de tener que construirse teniendo en cuenta cada triángulo o polígono de la escena, hace la intersección, sobre todo un clúster entero y no solo en unos pocos elementos. Además, le permite manejar el nivel de detalle según la distancia a la cámara de forma más eficiente, simplemente reconstruyendo los BVH de los objetos afectados utilizando los CLAS.
Un adelanto a cómo podrían ser las futuras GPU de NVIDIA
Los videojuegos a día de hoy apenas utilizan las capacidades de los modelos de alta gama, siendo este uno de los motivos por los cuales AMD no haya pensado en lanzar ni una RTX 9080 y mucho menos una RTX 9090. Si bien la idea de usar la computación vía GPU para tareas aparte de los gráficos ya tiene muchos años, esto solo ocurre si la GPU tiene potencia libre y requiere una comunicación continua entre la CPU y la GPU. Tanto el uso de las estructuras de aceleración CLAS en la construcción del árbol BVH para el Ray Tracing, como el Shader Execution Reordering está el concepto de procesar por paquetes, pero sobre todo de reducir la dependencia de la CPU

Al descartar la participación de la CPU en diversas tareas, nos encontramos con que no se han de ir haciendo envíos continuos desde la RAM a la VRAM y viceversa a través de las unidades DMA. Dicho de otra forma, la idea es usar los núcleos de la GPU para que estos realicen a través de programas shader gestionados y ejecutados desde el driver, funciones que de otra manera se implementarían a través de un hardware de función fija. Y se trata de un adelanto de lo que pretende NVIDIA en el futuro de sus arquitecturas gráficas.
La opción de NVIDIA será apostar por aumentar la cantidad de núcleos de la GPU y asignarlos de una u otra manera a dichas tareas. Obviamente no desaparecerá todo el hardware especializado, pero es una forma más de hacer dependientes los juegos a su propio ecosistema.