En la primera parte os comentamos por encima nuestras previsiones, con pruebas, de que UDNA tendrá una arquitectura más parecida a un Tile Renderer, en esta segunda parte os vamos a introducir la evolución del Frontend en las GPU para luego explicaros los cambios que veremos en UDNA.
El Frontend clásico o tradicional en una GPU
Hasta DirectX 11 y durante la era de OpenGL la forma de operar del Frontend de una GPU era siempre la siguiente:
- La CPU central del sistema prepara una lista de comandos que la GPU debe ejecutar. Dicha lista es fija y secuencial, es decir, se ejecuta en el orden en la que está escrita sin cambiar nada durante la ejecución de la misma.
- Cuando la GPU termina de ejecutar la lista, esta no puede hacer nada hasta comunicarle a la CPU para que genere una nueva lista y la envíe a la GPU de nuevo, lo que genera una fuerte dependencia de la CPU al dirigir esta el flujo de trabajo.
Esta es la forma clásica de gestionar la lista de comandos de la GPU, la cual a no ser que hablemos de juegos muy simples visualmente hablando se encuentra en desuso en los videojuegos. No obstante, tuvimos que esperar a la generación de PS4 y Xbox One para ver un cambio de paradigma con la computación asíncrona con la llegada de nuevas API como Vulkan, DirectX 12 y otras propietarias como GNM en PlayStation 4 para ver un cambio en el Frontend de las GPU. El cambio se hizo por primera vez en la arquitectura GCN, donde el procesador de comandos paso a desglosarse en dos pipelines distintos, uno para computación y el otro para gráficos.
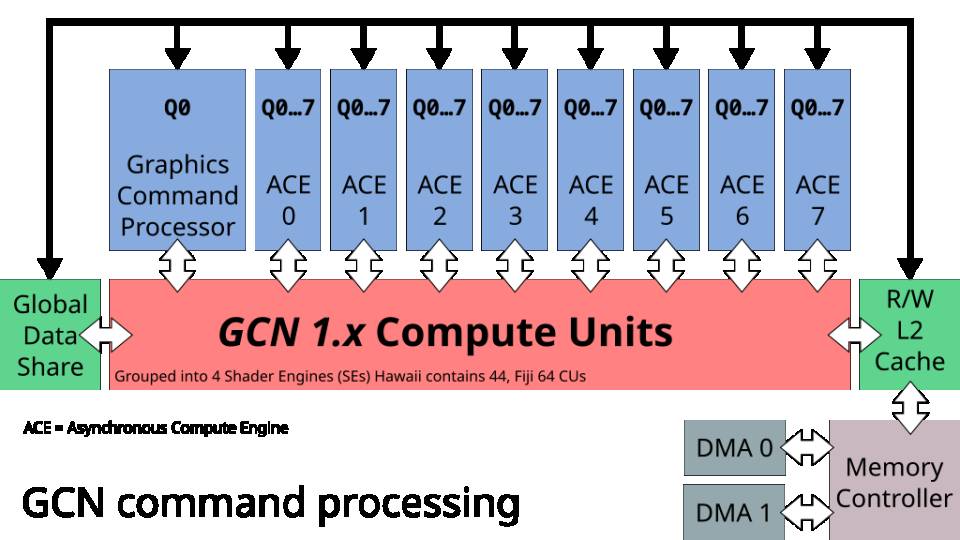
Ambos pipelines, el de gráficos y de computación se basan en listas de comandos creadas por la CPU, sin embargo, su naturaleza es diferente, aunque tanto en un caso como en otro las listas son generadas por la CPU y luego transmitidas desde el espacio de direccionamiento del microprocesador central, es decir, la RAM principal del sistema, al espacio de direccionamiento de la GPU a través de las unidades DMA, ya en la memoria de la GPU esta podrá leer las listas de comandos, tanto para computación como para gráficos.
- El procesador de comandos gráficos es el encargado de controlar la creación del frame usando el pipeline 3D convencional, usa una sola lista por el hecho que a no ser que hablemos de un Tile Renderer, por lo general una GPU renderiza una sola imagen en pantalla. Al contrario que los ACE, el GCP tiene acceso exclusivo a las unidades de función fija para gráficos.
- Por otro lado, los ACE se encargan de controlar la ejecución de listas de computación, estos son pequeños programas que se ejecutan directamente en los núcleos de la GPU y no utilizan el pipeline 3D, aunque se pueden utilizar también para gráficos su utilidad es más general. En este caso son varios de ellos, ya que suelen controlar listas muy pequeñas a la hora de hacer su trabajo, es más, en GCN y hasta el momento los 8 ACE han sido capaces de controlar hasta 64 listas de comandos de computación distintas. El motivo por el cual los ACE se llaman asíncronos es por el hecho que no tienen que seguir el ritmo de la generación de cada frame por lo que hay núcleos de la GPU que se pueden asignar a otras tareas aparte de la creación de gráficos.
No obstante, el mayor punto débil que tienen es que una vez que han ejecutado las listas de comandos, entonces ya no tienen nada que hacer. En ese caso los núcleos de la GPU se paran por completo y dejan de trabajar, lo cual supone un problema, ya que el secreto para el rendimiento de un chip gráfico en la actualidad no es la cantidad de núcleos y la frecuencia, sino asegurarse que estos trabajan, por lo que cuanto más complejo sea un videojuego más núcleos aproveche, pero también que su Frontend se encuentre lo suficientemente bien diseñado como para poder alcanzar mejores resultados con la menor cantidad de núcleos posible.
ExecuteIndirect
A partir de DirectX 12, con ExecuteIndirect y en Vulkan con DrawIndirect y DispatchIndirect, se le permitió a la GPU lanzar sus propios comandos de forma independiente a la CPU a través del uso de un búfer de comandos. Es decir, en vez de tener que esperar a que la CPU le lanzará una nueva lista de comandos, la GPU gano con ello la capacidad de reducir los periodos de inactividad ganando la capacidad para crear nuevos comandos que ejecutar sin permiso de la CPU. La diferencia con el planteamiento anterior era que históricamente:
- Las API gráficas clásicas (DirectX 11 y anteriores y OpenGL) eran altamente dependientes de la CPU, ya que esta tenía que armar cada comando de dibujado, validar los estados y mandarlo a la GPU.
- Todo ello creaba un cuello de botella entre la CPU y la GPU, donde la segunda, independientemente del número de núcleos se encontraba que si la CPU no era suficientemente rápida enviando comandos se quedaba esperando sin comandos que procesar.
- Lo peor de todo es que cada cambio de estado (shaders, búfers, texturas) debía pasar por la CPU siempre, es decir, la GPU pese a ser muy potente era una caja tonta que requería que la CPU le contase todo lo que tenía que hacer.

Para que os hagáis una idea del desastre que resultaba esto antes de la llegada de ExecuteIndirect, si por ejemplo queríamos hacer una escena con decenas de árboles, entonces, para cada árbol la CPU tenía que hacer para cada árbol:
- Calcular si se encuentra en el campo de visión.
- Crear la lista de comandos para cada árbol.
- Lanzar la lista de comandos para cada árbol.
Las consecuencias eran simples, si había demasiados elementos en pantalla entonces la CPU se saturaba y no podía mandar comandos a la GPU. Imaginad eso en consolas como PS4 y Xbox con núcleos famélicos en potencia como los AMD Jaguar. En cambio, con ExecuteIndirect/DrawIndirect la cosa cambia ya que:
- La GPU deja de mandar una lista de comandos individual para cada árbol, lo que hace es crear un búfer de comandos general que explica el proceso para cada árbol.
- El código le dice cuantos árboles tiene que procesar, en vez de pedirle permiso a la CPU para hacerlo, ejecutara la lista de comandos de forma reiterativa. Esto le permite, entre otras cosas, generar una lista de computación que le permita calcular que polígonos de los árboles no son visibles y manipular la lista de comandos de forma directa.
La idea como se puede ver era genial sobre el papel, pero ha resultado ser un enorme fiasco, la prueba de ello es que las versiones de muchos juegos desarrolladas para DirectX 12 tienen un rendimiento peor que sus contrapartes para DirectX 11. ¿Cómo es eso posible si con ello se elimino la sobrecarga de la CPU? La respuesta a ello se encuentra en el motivo real por el cual se creo el ExecuteIndirect y su equivalente para Vulkan.
Una forma de lavarse las manos
Si bien ExecuteIndirect parecía una buena idea sobre el papel, realmente no fue más que un complot por parte de los fabricantes de hardware y desarrolladores de las APIs gráficas para quitarse de encima buena parte de la responsabilidad y facilitar su trabajo. La forma de venderlo a los consumidores era simple: menos carga en la CPU significaban más frames por segundo. De lo que no hablaron fue de la letra pequeña del pacto, la que afectaba directamente a los desarrolladores. En vez de mejorar el Frontend de las GPU para que manejaran mejor el ExecuteIndirect, este lo dejaron intacto con consecuencias nefastas en el rendimiento de los juegos, nos vendieron el gran mito de que la CPU iba a respirar con menos carga gracias a ello y lo único que hicieron fue pasarle el problema a la GPU.

Es decir, seguimos teniendo una lista de comandos, la cual es secuencial en su ejecución, la única diferencia es que la gestión de la misma paso a llevarla la propia GPU, la cual tenía que sacrificar parte de la potencia bruta para gráficos para dedicarla a otras cosas. Todo ello siempre ha formado parte del marketing para vender a las tarjetas gráficas como productos más allá de los videojuegos, y es cierto, esto ha hecho que fueran adoptadas por la computación de alto rendimiento (científica, militar) y posteriormente ha permitido desarrollos como el de la IA, pero en videojuegos es distinto, ya que si el núcleo de una CPU tiene suficiente potencia para encargarse, por ejemplo, de las físicas de un juego, entonces no se usará la GPU para ello. Pero en el caso de ExecuteIndirect no hablamos de derivar trabajos generales, sino tareas que antes realizaba el driver.
A todo ello lo llamaron GPU Driven rendering, se vendió que la idea era que en vez de esperar una lista secuencial de comandos, esta se podía dividir en varias listas distintas y que una parte de los núcleos de la GPU se encargasen de controlar una parte de la lista de comandos. Muy bonito sobre el papel, pero nos lleva a una pregunta: ¿tiene capacidad la GPU para leer y subdividir la lista en varias más pequeñas? No, eso tenía que correr de la mano de los desarrolladores al 100%, no hacerlo la API ni el propio hardware. ¿A que nos remitimos como prueba? A que no haya habido un salto generacional real en los últimos años en videojuegos.
Mesh Shaders
El primero de los cambios que se publicito bajo ExecuteIndirect fueron los Mesh Shaders, los cuales se anunciaron como el mayor cambio en el pipeline geométrico, el que ocurre antes del rasterizado y donde se manejan vectores y polígonos. Los Mesh Shaders no son más que una etapa programable en el pipeline 3D de la GPU que reemplaza al Input Assembler, los Vertex Shaders y los Geometry Shaders, el cual tiene la particularidad de ser más flexible ya que entre otras cosas permite generar la malla final, es decir, podemos añadir nueva geometría desde la GPU sin preguntarle a la CPU y permite realizar cosas como eliminación de geometría no visible y eliminar o añadir nivel de detalle de un modelo desde la GPU sin tener que pasar por la CPU.

Dicho de otra forma:
- Los Mesh Shaders eliminan la necesidad de describir cada vértice desde la CPU, le da control total a la GPU para generar la geometría.
- Gracias a ExecuteIndirect, la GPU puede decidir que grupos de Mesh Shaders despachar.
Por ejemplo, podemos escribir un shader de computación que analice la visibilidad de los objetos y luego construya un búfer de argumentos que sea leído a través de ExecuteIndirect para que los Mesh Shaders generen las primitivas finales. Todo ello sin que la CPU tenga que intervenir en todo el proceso. ¿Suena bien no? Pues la mayoría de los estudios de desarrollo han prescindido de usarlos. El motivo de ello es que muchos estudios llevan mucho tiempo trabajando con el pipeline geométrico clásico y el hecho de migrar a un modelo basado en los Mesh Shaders significa reescribir gran parte del código, lo cual, económicamente para un estudio promedio es un esfuerzo que no compensa.
Ray Tracing
Si bien el Ray Tracing que vemos actualmente en los videojuegos no es lo que se dice trazado de rayos puro y duro, sino que se combina con la rasterización para solucionar problemas visuales que esta última no puede hacer bien, que son todo aquello que simula el comportamiento de la iluminación indirecta, que es la que se da cuando un haz de luz incide sobre un objeto. Obviamente hablamos de reflejos, sombras, refracción lumínica, etc. Los cuales son pesimamente ejecutadas con el pipeline clásico basado en la rasterización, pero hemos de tener en cuenta que sin el ExecuteIndirect el trazado de rayos no habría sido posible.

Sin ello, nos encontraríamos que en el actual Ray Tracing híbrido sería imposible invocar rayos indirectos, es decir, aquellos que son de un rebote de un rayo de luz sobre un objeto sin invocar a la CPU. Otros afectados son los efectos de postprocesado sobre el frame final que con ExecuteIndirect se pueden iniciar desde la propia GPU en forma de un Compute Shader de inicio y no depender de la CPU para ello. Esto incluye también los algoritmos de aumento de resolución actuales como el PSSR, el DLSS y FSR, los cuales sin este importante cambio no se podrían ejecutar con la misma celeridad que lo hacen.
La situación real del ExecuteIndirect
En pleno 2025, casi diez años después de su presentación, el ExecuteIndirect se ha convertido en un fiasco y con ello el llamado GPU Driven Rendering, ya que los aficionados no han visto un salto técnico considerable en los últimos años en lo que a los videojuegos se refiere. La causa de ello la hemos explicado, los creadores de las API y los de las tarjetas gráficas, quienes se encargan de crear los drivers se han lavado las manos y le han pasado la tarea de que ciertas funciones las realice la GPU de forma directa y esto significa que lo haga la propia aplicación, lo que se traduce en que lo hagan los programadores.
Como diría Spider-Man, un gran poder supone una gran responsabilidad, la existencia del ExecuteIndirect cambio las normas del juego en DirectX 12 y cosas que antes tenia que manejar el driver e incluso la API cayeron en manos de los propios desarrolladores y su habilidad. ¿El resultado? decenas e inclusos cientos de juegos de golpe en sus versiones para DX12 terminaban teniendo menos rendimiento que en sus contrapartidas para DX11, esto decelero la adopción del hardware necesario y retraso varios años el avance tecnológico. De ahí a que la actual generación aparentemente no haya tenido cambios respecto a la anterior.

De ahí a que mejoras como los Mesh Shaders terminaran en saco roto, ya que una de las mejoras de este era la capacidad de generar nueva geometría desde la propia GPU pudiendo añadir mucho más detalle a los modelados de los personajes. Esto se traduce en poder crear y destruir geometría y con ello el nivel de detalle sin permiso de la CPU y sin necesitar una unidad de teselación para ello. Si bien parte de los problemas se han paliado a base de automatizar ciertas funciones a través del driver, este se ejecuta en el microprocesador central y supone no aprovechar bien las capacidades del ExecuteIndirect, sino más bien un parche para que DirectX 12, Vulkan y otras API sean más digeribles.
El otro problema tiene que ver con el hardware, precisamente con AMD que es la principal culpable de ello, ya que hasta RDNA 3, y recordemos que las consolas se basan en RDNA 2, no se vio un procesador de comandos con la capacidad de operar con ExecuteIndirect de forma eficiente. Es más, este es el motivo por el cual para los Workgraphs, el reemplazo de ExecuteIndirect, deberemos esperar a la siguiente generación de consolas.
Workgraphs
La solución a los problemas del ExecuteIndirect van a ser los Workgraphs, pero no lo decimos nosotros, sino los propios fabricantes (NVIDIA y AMD) y también los creadores de las API más usadas, más que nada porque los Workgraphs o grafos de trabajo serán lo que reemplazarán a las listas de comandos tradicionales, lo que supondrá cambios importantes en el hardware de las futuras GPU. Actualmente es posible implementarlos a través de shaders de computación, pero a partir de arquitecturas como UDNA estos se verán manejados por la GPU gracias al Frontend renovado.
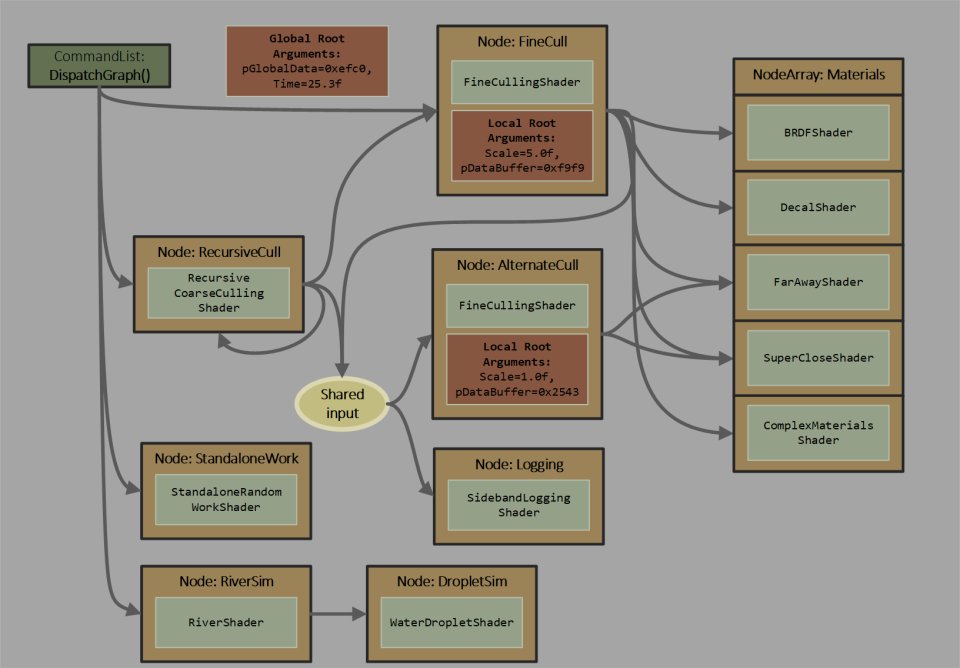
Sin embargo, no es magia y esto tiene una explicación, al pasar la los comandos de una lista a grafos la información se organiza de la siguiente manera:
- Nodos (o vértices): son los puntos o elementos del grafo. Los nodos son tareas o programas que la GPU debe ejecutar. En realidad, los nodos son las pequeñas listas de comandos asíncronas que teníamos hasta ahora
- Aristas (o enlaces): son las conexiones o relaciones entre esos nodos. Las aristas representan qué tareas dependen de otras para ejecutarse y cuales son independientes y pueden correr en paralelo.
De esta forma la GPU tiene la información suficiente para gestionarse a sí misma, ya que conoce el nivel de dependencia entre las diferentes tareas, cuales se pueden ejecutar primero, cuales se pueden realizar sin depender de otras. Todo ello sin necesidad de que la CPU lo indique a través de listas de pantalla y sin que se tenga que invocar explícitamente un ExecuteIndirect, simple y llanamente el grafo le da la información suficiente al chip gráfico para que sepa que puede paralelizar y que no, que tiene preferencia antes de otras cosas.
Para entender mejor la evolución desde las listas de comandos vía ExecuteIndirect al uso de WorkGraphs y lo que esto supone en futuro a medio plazo, hemos decidido hacer una tabla que resume los cambios principales.
| Característica | ExecuteIndirect | Work Graphs con ejecución fuera de orden |
|---|---|---|
| Unidad de trabajo | Lista de comandos (Command List) enviada a una cola. | Nodo = microlista de comandos dentro de un grafo. |
| Relación entre listas | Definida por el programador con barriers, fences y events. | Definida explícitamente en el grafo mediante aristas (dependencias lógicas, de recursos y/o espaciales). |
| Orden de ejecución | Fijo según lo envía la CPU/driver, con intercalado limitado por colas. | Decidido dinámicamente por el command processor de la GPU según dependencias y heurísticas de eficiencia. |
| Control | La CPU con el driver determina cuándo cada lista entra en ejecución. | El hardware interpreta el grafo y reordena nodos automáticamente, sin intervención del driver. |
| Optimización de caché | Depende de que el programador organice listas pensando en locality. | El hardware puede agrupar nodos por región de pantalla u objetos, maximizando cache locality. |
| Reacción a carga desigual | Difícil: requiere reestructurar listas o usar fine-grained barriers. | Automática: nodos listos se despachan en cuanto hay recursos, balanceando carga en tiempo real. |
| Ámbito típico | Gráficos o cómputo separados en colas específicas. | Gráficos, cómputo, ray tracing y copias pueden coexistir en el mismo grafo y optimizarse juntos. |
El Frontend de UDNA
Tras esta larga, pero necesaria introducción vamos a hablar de los cambios en el Frontend en la arquitectura UDNA, si bien todos ellos se verán también en las GPU de otras marcas, es necesario entender la evolución para verle el sentido a los cambios y que no se vean como aleatorios. Claro que hay que aclarar que si bien es cierto que se pueden aplicar los Workgraphs a través de shaders de computación, la clave esta siempre en delegar las tareas recursivas y repetitivas a piezas de hardware concretas para que puedan ejecutarlas en paralelo. Si bien UDNA continuará procesando listas de comandos de forma tradicional para poder ejecutar todavía software creado alrededor de las API gráficas antiguas, será el uso de Workgraphs lo que marcará la diferencia respecto a generaciones anteriores.

Hasta el momento la gestión de los hilos y la generación de nuevos comandos dependía exclusivamente del procesador de comandos, en UDNA la cosa cambiará con el añadido de dos nuevas piezas en la arquitectura a nivel más local. Por un lado tenemos a los Local Launcher a nivel de cada núcleo de la GPU, los cuales se verán acompañados por otra unidad, el Shader Wave Coalescer. A nivel de Shader Array o Shader Engine veremos el WGS o Workgraph Scheduler, dos piezas inéditas en las actuales arquitecturas que están optimizadas no solo para mejorar el rendimiento con los Workgraphs, sino también en los pocos títulos basados en ExecuteIndirect.
Work Graph Scheduler (WGS)
El principal cambio en UDNA es el añadido de un planificador intermedio a nivel del Shader Engine, el cual agrupa a varios núcleos de la GPU o WGP en el caso de UDNA alrededor de una misma caché compartida un nivel por encima de la caché local. Dicha caché ya la vimos en RDNA como la caché L1, pero la diferencia es que en UDNA dejará de ser de solo lectura para pasar a ser de lectura y escritura. No obstante, aquí el punto importante es el llamado Workgraph Scheduler (WGS), donde tenemos uno en cada Shader Engine.
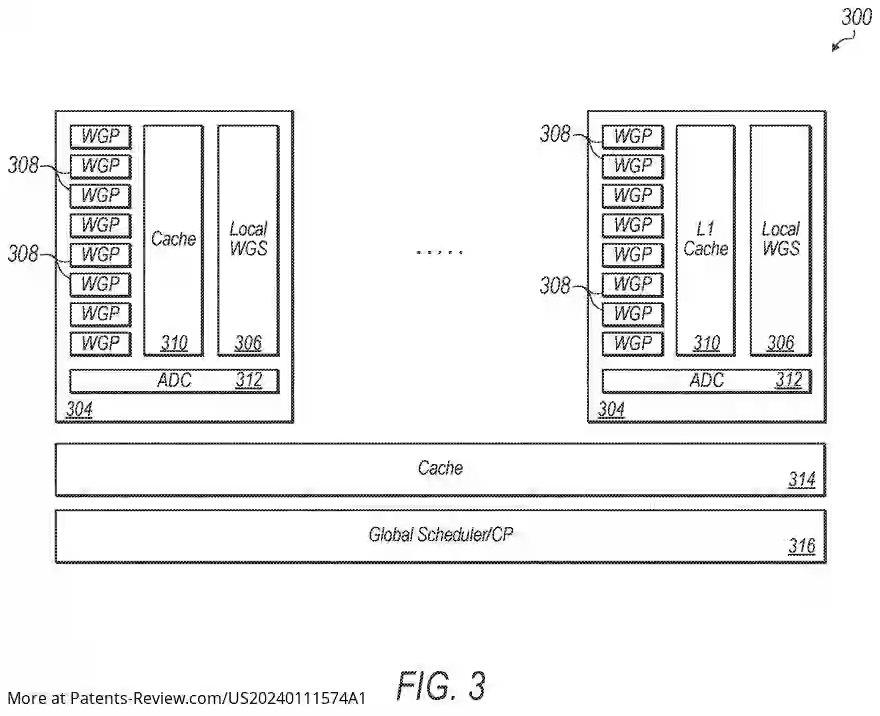
Dicha unidad lee de la caché global (L2) las listas de trabajo previamente creadas por el procesador de comandos global, la idea es reducir el impacto sobre la L2 a la hora de leer los comandos y trasladarlos al Shader Engine que los ha de procesar. Por lo que reduce el tráfico interno global y permite que el trabajo se maneje en cada shader engine de forma local. Así pues, el trabajo del procesador de comandos que se dedicaba a repartir el trabajo entre los diferentes núcleos de la GPU ahora lo hace el Workgraph Scheduler (WGS). En el caso de que una parte de un workgraph y sus dependencia sean demasiado grandes, entonces el trabajo se dividirá entre los varios núcleos del Shader Engine, los cuales leerán la caché L1 compartida para saber que trabajo han de hacer.
Además, de repartir las tareas, el WGS evalúa la cantidad de trabajo por hacer respecto a la capacidad de trabajo de los WGP del Shader Engine. Para ello lee la caché L1 (local a nivel de Shader Engine) donde se encuentran tanto el trabajo indirecto generado por cada WGP y que no ha podido procesar y el obtenido desde la cache global. A partir de ese punto pueden ocurrir dos cosas:
- Si la capacidad de trabajo es menor al trabajo a realizar se libera de la carga extra y se reparte a otros shader engines. El planificador global en en procesador de comandos central ignorara a ese Shader Engine hasta próximo aviso.
- Si no esta sobrecargado de trabajo se ira asignando trabajo a ese Shader Engine hasta que se sature. La repartición de trabajo se hace ya no a nivel de núcleo de forma aleatoria, sino que se espera a llenar de tareas a los Shader Engine antes de pasar al siguiente.
Local Launcher
La forma de repartir el trabajo entre los diferentes núcleos de la GPU es trabajo del SPI (Shader Processor Input) el cual se encuentra en el procesador de comandos. Su trabajo es planificar y repartir las diferentes olas que llegan desde el procesador de comandos entre los diferentes núcleos de la GPU. La realidad es que si el SPI es demasiado lento haciendo su trabajo y no le da tiempo a repartir las tareas a los diferentes núcleos de la GPU, entonces se convierte en un cuello de botella, pero tampoco puede enviar más tareas a hacer si realmente no hay tareas que repartir. En arquitecturas anteriores a UDNA, los núcleos de la GPU eran esencialmente ejecutores: recibían wavefronts desde el SPI y los procesaban.
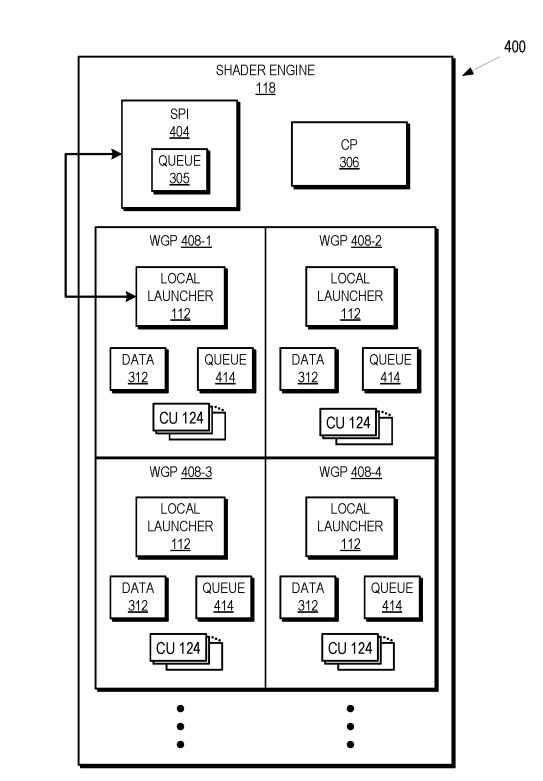
Pues bien, con UDNA la cosa cambiará por completo, ya que cada núcleo contendrá en su interior una nueva unidad, a la cual se la ha bautizado como Local Launcher. Gracias a esta nueva unidad cada núcleo puede lanzar nuevas tareas o comandos internos desde el propio, sin necesidad de esperar a la inyección desde el SPI. La única limitación clara es que exista memoria libre en los registros para ello, ya que si estos se encuentran llenos no se pueden generar nuevas tareas a realizar, más que nada por falta de espacio. Con ello los núcleos de la GPU ganan en autonomía y no dependen del SPI. Cuando se generan nuevas tareas/olas a hacer y no se pueden almacenar a la caché local, entonces se exporta a la caché L1 donde serán manejados por el Workgraph Scheduler para que los asigne a los otros núcleos y mantenerlos ocupados la mayor parte del tiempo.
La ventaja de los Local Launcher es que hace que no tengan que esperar al SPI para tener nuevas listas de comandos a ejecutar, ya que este envía las olas de forme secuencial a los diferentes núcleos de la GPU, provocando un cuello de botella que crece cuanto más núcleos tenga esta. Gracias a esta nueva pieza de hardware varios núcleos pueden estar generando y despachando listas de comandos en paralelo en vez de competir por la atención del SPI.
Streaming Wave Coalescer
La siguiente unidad dentro de los núcleos de la GPU es el llamado Stream Wave Coalescer, aunque al contrario que las dos unidades anteriores, no es una novedad de AMD, sino más bien una adaptación de la Thread Sorting Unit o TSU de las arquitecturas Intel Xe. Por lo que su funcionalidad es literalmente la misma. Su trabajo es el de ordenar y reemitir los hilos de las diferentes olas para evitar los problemas que se dan cuando hay divergencias en los hilos. En realidad no deja de ser una implementación en el hardware del Shader Dispatch de DXR, por lo que forma parte del frontend de la GPU, pero esta orientado de cara al trazado de rayos.
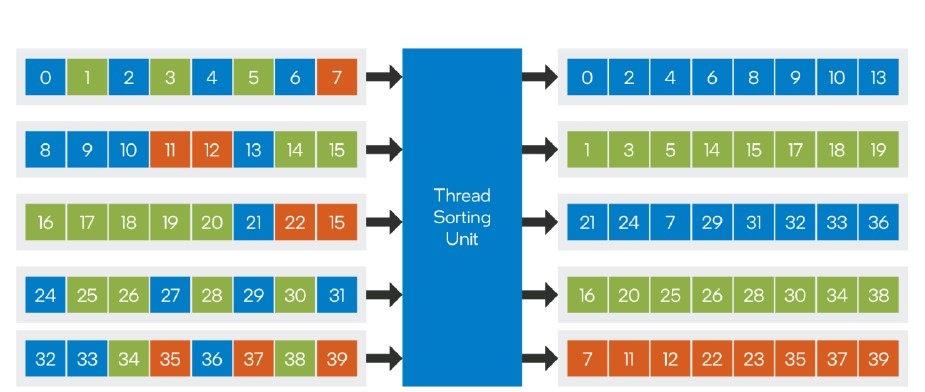
El talón de Aquiles de toda GPU son las instrucciones con salto, ya que al contrario que las CPU, estas no tienen buenas unidades de predicción de saltos, lo que provoca que el código divergente afecte negativamente el rendimiento en toda GPU. A la hora de ejecutar las instrucciones, las GPU utilizan unidades SIMD o SIMT, las cuales ejecutan una misma instrucción en varios datos en paralelo. Es por ello que los hilos se organizan en olas que agrupan todos los hilos con la misma instrucción. Sin embargo, si hay hilos de una ola que toman caminos diferentes, unos por entrar en un salto y otros no, es cuando ocurre la divergencia de hilos.
Al final, cuando ocurre la divergencia no todos los hilos se pueden ejecutar en paralelo, lo que llevará a que las ALU de la unidad SIMD correspondientes a los hilos aplazados estén sin hacer nada. Es decir, ha de ejecutar secuencialmente la ola y añadir ciclos de reloj adicionales para solucionar una misma ola. Pues bien, la trampa para ello es una unidad que identifique en el código del shader donde se encuentran los saltos. Esto funciona de forma muy parecida a una Branch Prediction Unit de una CPU actual, pero de forma muy simplificada. A través de leer la caché de instrucciones del núcleo de la GPU, lo que hace es identificar los saltos y etiquetar el código correspondiente al salto.
Aquí es donde entra el Stream Wave Coalescer o SWC a partir de ahora. Una nueva unidad dentro del núcleo de la GPU que veremos en las arquitecturas UDNA. Su funcionamiento es que agrupará los hilos bajo una misma etiqueta en una memoria intermedia llamada “cajas de ordenamiento” o sort bins. Si una caja se llena significará que ya tiene suficientes hilos para formar una ola completa y el SWC la emitirá a los registros de la Compute Unit para ser ejecutada de forma habitual.
Con esto terminamos, la segunda entrega de la trilogía. En la tercera parte tocaremos ya definitivamente el Backend en UDNA. Esperamos que os haya gustado.