A través de una serie de patentes, publicadas por la propia AMD, vamos a hacer un viaje a la futura arquitectura gráfica de AMD, la cual como sabréis recibe el nombre de UDNA, ya que con ella AMD unirá el desarrollo de CDNA (su GPU para computación de alto rendimiento y Machine Learning) y RDNA (su GPU para gaming con capacidades de Ray Tracing). Al mismo tiempo, esto lo contrastaremos con las informaciones de la arquitectura que han aparecido en los últimos días en la red. Es más, tal es el volumen de información que este artículo se dividirá en varias partes distintas.
El rumor de la memoria LPDDR nos dice más de lo que parece
En uno de los últimos vídeos de MLID, él comenta que las dos variantes de gama baja de la arquitectura UDNA llamadas AT4 y AT3 no usarían memoria GDDR6 o GDDR7, sino memoria LPDDR5X y LPDDR6 respectivamente. El motivo de ello es que el mismo chiplet GPU que se usará en las tarjetas gráficas dedicadas también lo veremos junto a la CPU compartiendo espacio conectados en un mismo interposer en común. En dicho proceso el IOD se moverá junto a la GPU para ir al mismo chip, por lo que al contrario de lo que especulábamos donde decíamos que el IOD podría moverse hacia el interposer, no sería así.

En todo caso, el concepto de un chip separado en un modulo multichip donde la CPU va por un lado y el resto del SoC en otro chip no es nuevo. Ya lo vimos en sistemas como la Xbox 360 Slim y también en Wii U, por lo que aquí AMD no ha inventado nada y una configuración que lleva años usándose. La clave aquí es que ellos pueden usar un mismo chiplet de GPU para múltiples sistemas distintos, lo mismo que ocurre con los CCD de las diferentes arquitecturas Zen, los cuales son los mismos en las CPU Ryzen, Threadripper y EPYC en cada generación, suponiendo un cambio importante en la estructura de costes.
Sin embargo, MLID da un motivo para este movimiento en la gama baja y media baja por parte de AMD y es el hecho de que NVIDIA para asegurarse en exclusivo toda la memoria GDDR7 paga cantidades ingentes a los fabricantes, esto deja a AMD sin maniobra. ¿La solución? Tirar de la memoria LPDDR, ya que NVIDIA no se atreverá a toserle a los ensambladores que son también quienes montan y venden sus tarjetas gráficas y portátiles gaming con sus GPU. Claro está, que las GPU son altamente dependientes del ancho de banda y el hecho de pasar a una memoria con peor caudal de datos supone un problema en el rendimiento, a no ser que en la arquitectura UDNA se de el salto a que la GPU sea un Tile Renderer.
¿Por qué creemos que UDNA es un Tile Renderer encubierto?
Las pruebas de ello las daremos luego, pero el motivo de ello es que un Tile Renderer tiene una carga sobre el ancho de banda mucho más pequeña, el motivo de ello es que renderiza no la escena como una sola imagen, sino que divide la imagen en bloques muy pequeños llamados Tiles, los cuales caben en la memoria interna de la GPU. Esto provoca que una gran cantidad de operaciones gráficas se pueden realizar dentro del propio chip, sin tener que consultar la memoria externa.

Esto se puede hacer gracias a que en la rasterización se trabaja de manera local, es decir, las primitivas gráficas actúan en exclusiva sobre su área de pantalla, ya sean estas vértices, polígonos, fragmentos o píxeles texturizados. Esto además permite que las GPU tengan una gran cantidad de núcleos con sus memorias cachés locales, pero sin tener que preocuparse por un complejo mecanismo de coherencia de caché. Sin embargo, esto tiene un punto débil y es con el Ray Tracing, ya que un rayo puede afectar a diferente partes de la pantalla, esta divergencia se convierte en un problema para el Tile Rendering, lo que nos lleva a los cambios que ha hecho AMD y muy probablemente hará también NVIDIA en el FrontEnd de la GPU, empezando por UDNA.
En todo caso, las GPU para dispositivos de bajo consumo como PowerVR (utilizado en los chips de Apple), Mali y Adreno (Qualcomm) son Tile Renderers y son uno de los motivos por los cuales son mucho más eficientes. El coste energético de una operación con la memoria gráfica es muy alto en comparación cuando se puede resolver una instrucción exclusivamente con memoria interna. Desgraciadamente, no todos los datos caben dentro de la memoria interna de una GPU y se sigue necesitando memoria externa, pero la tendencia es esa, en localizar dentro del chip la mayoría de operaciones con tal de mejorar la eficiencia en el consumo.
La tendencia ya estaba ahí
Actualmente las GPU para PC y consolas no son un Tile Renderer, sino algo a medio camino llamado Tile Caching, lo cual no es otra cosa que la mayoría de operaciones ya no se resuelven sobre la memoria, sino sobre la cache global, L2 habitualmente, evitando que muchas de ellas terminen solucionándose en la memoria de vídeo. Por desgracia la caché es limitada y su funcionamiento depende de que la GPU realice un flush, que es volcar a la VRAM los datos de la misma, rompiendo la funcionalidad del Tile Caching.ç
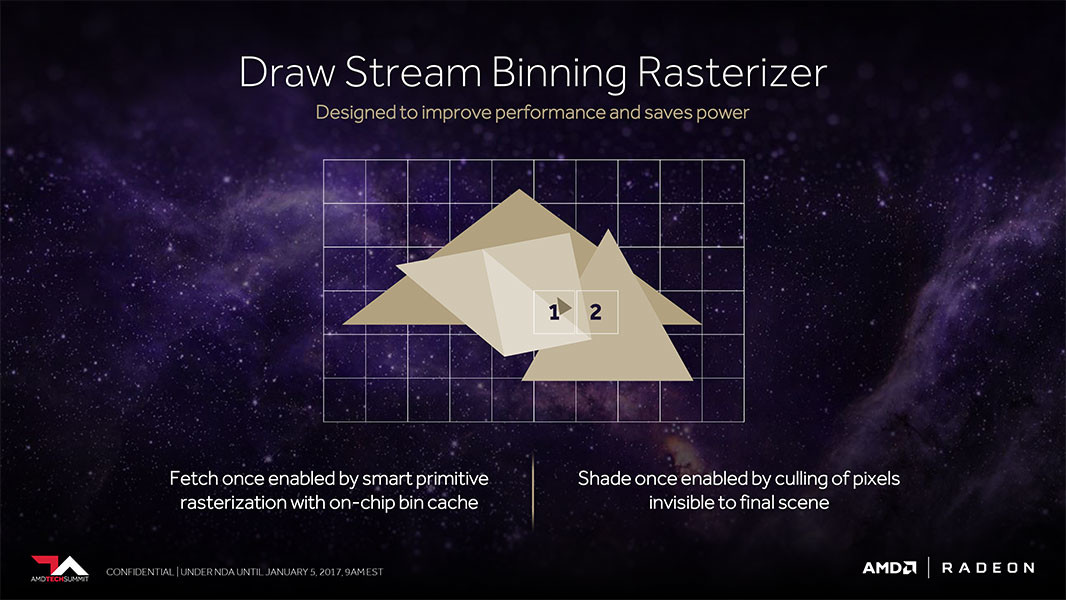
¿La solución? Aumentar la cantidad de cache L2 (que es lo que hizo NVIDIA con las RTX 40 en adelante) o añadir una Victim Cache como L3 por debajo, que es lo que hizo AMD. Si bien esto aumenta la latencia, no ocurre como con la memoria DDR tradicional cuyas latencias son bajas, las de las memorias GDDR y también las LPDDR tienen una latencia mucho más alta, lo que da margen para colocar cachés de varias decenas de MB. No obstante, no son Tile Renderers, por el hecho que lo que hace un Tile Renderer es clasificar primero la geometría según su posición en pantalla y luego crear listas de pantalla por cada Tile, esto no lo hacen todavía ni las GPU de NVIDIA ni las de AMD.
Entonces, ¿Qué es lo que hacen? Pues lo que hacen es ordenar los fragmentos ya rasterizados, es decir, durante la etapa de proyectar la escena 3D compuesta por polígonos sobre el búfer de imagen, pues esos polígonos los llamamos fragmentos y lo que hacen las arquitecturas actuales es ordenarlos en dicha etapa, para comportarse como un Tile Renderer, pero solo para la etapa de rasterizado.
¿Qué pruebas tenemos?
Pues ni más ni menos que una patente, titulada «Distributed geometry» y cuyo abstracto inicial nos dice lo siguiente:
Se divulgan sistemas, aparatos y métodos para realizar trabajo de geometría en paralelo en múltiples chiplets. Un sistema incluye un procesador de chiplets con múltiples chiplets para ejecutar trabajo gráfico en paralelo. En lugar de contar con un distribuidor central que reparta el trabajo entre los chiplets individuales, cada chiplet determina por sí mismo el trabajo que debe realizar. Por ejemplo, durante una llamada de dibujo (draw call), cada chiplet calcula qué porciones debe obtener y procesar de uno o más index buffers correspondientes a uno o más objetos gráficos de la llamada de dibujo. Una vez que se calculan dichas porciones, cada chiplet obtiene los índices correspondientes y los procesa. Los chiplets realizan estas tareas en paralelo e independientemente unos de otros. Cuando se procesan los index buffers, uno o más pasos posteriores en el proceso de renderizado gráfico se ejecutan en paralelo por los chiplets.
Si bien el concepto chiplets nos puede parecer confuso, cuando veamos los cambios en el Frontend en UDNA lo entenderemos mucho mejor, ya que al igual que ocurre en el caso de las APU/SoC AMD Ryzen que son monolíticas en vez de estar disgregadas por chiplets, pero integran la misma circuitería que los CCD pues aquí va a ocurrir lo mismo. Las GPU UDNA pese a estar montadas en una sola pieza, van a tener la capacidad de disgregarse en chiplets si es necesario. En todo caso, este detalle os quedará más claro en una futura entrada.
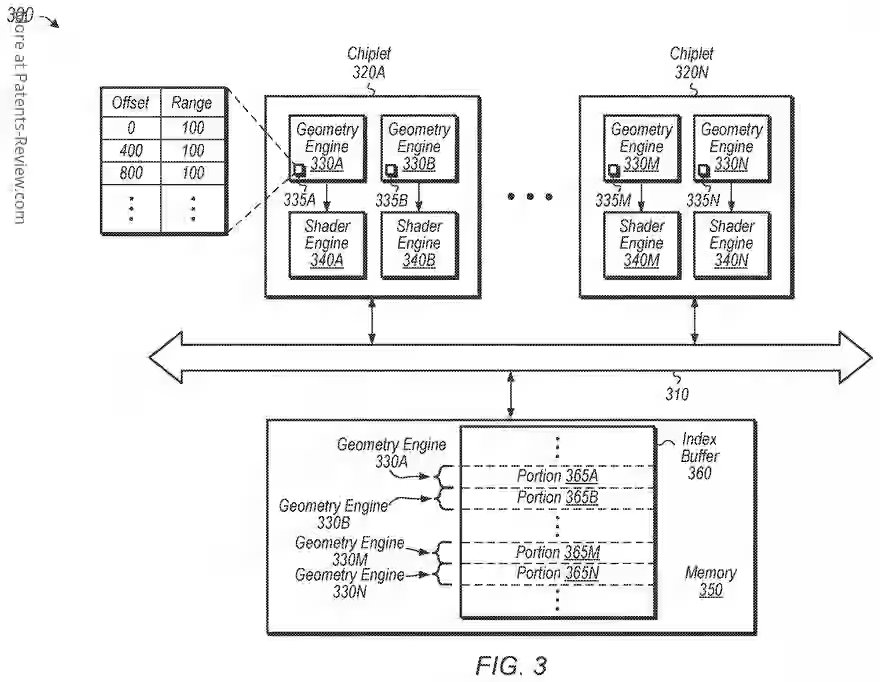
Aquí la clave es el Index Buffer, el cual contiene la información de como esta distribuida la geometría de la escena, para hacerlo se prerrenderizada el siguiente frame, pero no con la información completa, sin calcular shaders de ningún tipo y tampoco texturas. Simplemente la idea es tener un mapa de la geometría de la escena para generar el ID Buffer para darle una etiqueta a cada objeto en pantalla, el otro es generar el Z-Buffer o búfer de profundidad. El búfer de imagen final no se mostrará en pantalla y tampoco pasará por la fase de texturizado, sino que el objetivo es poder mapear la geometría según su posición en pantalla en el Index Buffer.
No es Tile Renderer, pero casi
Hemos de partir que el Tile Rendering requiere dividir la escena en bloques (tiles) para lo cual primero hay que clasificar la geometría según su posición de pantalla, de ahí a que la calculemos ante para luego reccorer el Index Buffer y decidir que polígonos van a cada tile. En el esquema de la patente, la división es a nivel de reparto de trabajo, ya que aquí el Geometry Engine procesa su porción independiente del búfer de índices, por lo que solo habría que añadir la lógica de clasificar las primitivas por tile para obtener lo que es un Tile Renderer.
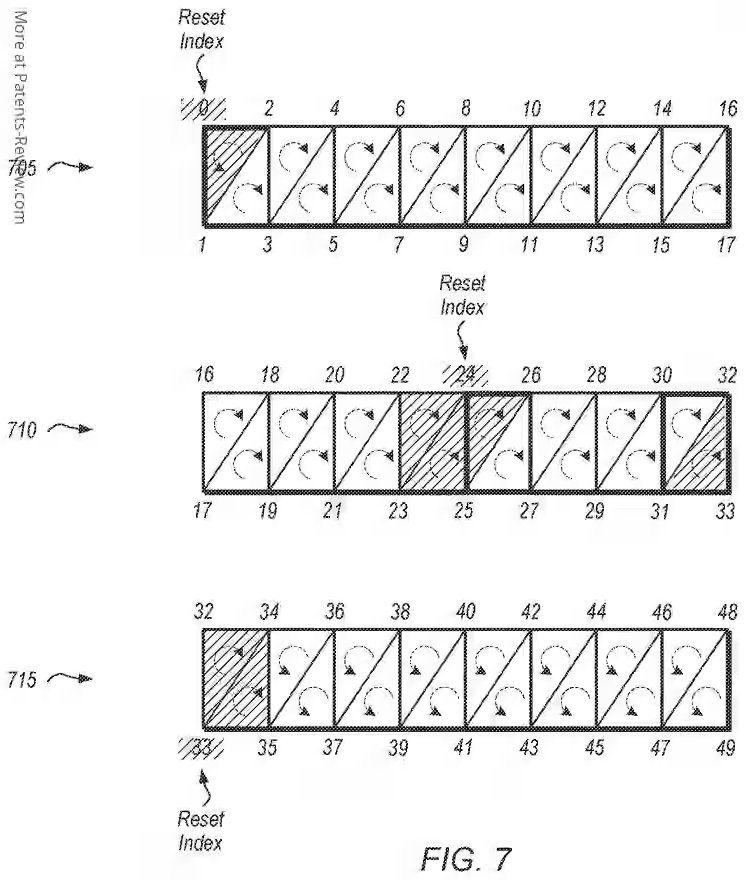
Es más, aquí el trabajo de un Geometry Engine no es el de generar geometría, ya que eso lo hacen los shaders. Más bien su trabajo es que cuando se aplica el algoritmo para eliminar geometría no visible, los Geometry Engine eliminan de su Index Buffer la información que no se va a ver para no procesarse después. También funcionan a la inversa y le permiten a los Mesh Shaders añadir nueva geometría a los modelos ya existentes de forma inmediata. El caso es que aquí cada Geometry Engine se encarga de una parte de la pantalla, así pues, lo que tenemos son megatiles, por lo que no es un Tile Renderer al 100% y la división dependerá de la cantidad de Shader Engine que tenga la GPU.
Por lo que si bien cada Geometry Engine puede trabajar sin necesidad de sincronización, lo cual encaja en un modelo de renderizado por tiles, y esto permite que puedan procesarse los diferentes bloques de la escena en paralelo. Claro está que aquí necesitaríamos una división ya más a nivel de núcleo de la GPU o de Compute Unit. El cual dividiría los megatiles en un tamaño más pequeño con el que ya se podría trabajar. No obstante, no se trata de un Tile Renderer puro ya que:
- La patente reparte la información del Index Buffer en rangos lineales (offsets), por lo que para ser un Tile Renderer completo haría falta una unidad de Binning o de clasificación espacial que clasificará por posición en pantalla, no solo por índice.
- Se necesitaría que la GPU tuviera cachés internas para almacenar todos los vértices, fragmentos y texturas de un tile, evitando accesos a memoria externa.
No obstante, todavía no podemos hacer afirmaciones tan directas, por lo que las haremos en futuras entradas.
Conclusión
De cara a UDNA, AMD evolucionara sus GPU a una arquitectura distribuida, más cercana a lo que es un Tile Renderer que sus GPU actuales motivada por tres motivos principales:
- NVIDIA se encuentra monopolizando el acceso a la GDDR7, lo que fuerza a AMD a usar LPDDR5X y LPDDR6 en ciertas gamas.
- El uso de memoria LPDDR supone el uso de soluciones cercanas al Tile Rendering, las cuales tiene un impacto menor sobre la memoria.
- La idea de tener Geometry Engine independientes procesando en paralelo es el paso necesario para que el Frontend pueda clasificar y procesar tiles localmente y dividir la escena por tiles.
Sin embargo, vamos a dejarlo por el momento, ya que los cambios en el FrontEnd vamos a hablarlos en el siguiente artículo y a enlazar con la información del actual. Una vez llegado aquí, esperamos que os haya gustado.