Si bien aún falta para que AMD presente su arquitectura UDNA de forma oficial, así como la confirmación definitiva de los detalles de la misma. Lo que sí que sabemos es que se utilizará en la siguiente generación de consolas de videojuegos. Es por ello que hemos decidido crear este reportaje, el cual será inicialmente especulatorio, pero que se irá ampliando con el tiempo a medida que se confirmen o desmientan las informaciones alrededor de la próxima generación de GPU de la marca liderada por Lisa Su.
UDNA, la unión de CDNA y RDNA
Sin duda, uno de los mayores errores de AMD en cuanto al diseño y creación de nuevas GPU no ha sido otro que tener dos arquitecturas totalmente dispares para ello. Mientras que la gama Radeon basa actualmente sus GPU en evoluciones paulatinas de la arquitectura RDNA, en el caso de las AMD Instinct utilizadas para IA avanzada y sobre todo computación de alto rendimiento lo que tenemos es una evolución de GCN llamada CDNA, pero no sería bueno llamarlas tarjetas gráficas desde el momento en que carecen de las unidades de función fija para ello, de la capacidad de gestionar un anillo gráfico y para no tener, al contrario que las Radeon, carecen de salidas de vídeo.

Por otro lado, AMD con RDNA decidió no darles capacidades de Machine Learning (IA) al nivel de la competencia por el hecho de que lo veían como una competencia a sus AMD Instinct basados en CDNA, al mismo tiempo que tampoco le otorgaron un Ray Tracing de calidad para sabotear a NVIDIA. El problema es que poco puedes hacer contra alguien que tenía por aquel entonces el 80% del mercado y ahora ya tiene el 90% de cuota. Además, que mantener dos arquitecturas gráficas distintas para una empresa como AMD es simplemente un suicidio.
Así que alguien inteligente dentro de la empresa dijo: ¿y si nos dejamos de tonterías y hacemos una arquitectura unificada? Es ahí donde nace UDNA, la cual no solo es una evolución de RDNA, sino que viene a reemplazar a CDNA. Por el momento sabemos poco, y lo que sabemos se infiere de patentes de la propia AMD y filtradores de información. No obstante, todo ello resulta suficiente como para compartirlo.
El Frontend de UDNA
El primer elemento del que hablaremos es del Frontend, el cual se encuentra en todas las GPU y cuyo elemento principal es el procesador de comandos, el cual en AMD no ha evolucionado desde las últimas generaciones de GCN, pero que en UDNA va a tener una evolución importante. En toda GPU contemporánea, el Frontend se encarga de preparar y organizar los datos antes de que lleguen a los núcleos de la GPU, aceleradores y diferentes unidades de función fija que se encuentran dentro del chip. Por lo que, comparativamente con una CPU, es también la parte que se encarga de captar datos e instrucciones desde y hacia la memoria externa.
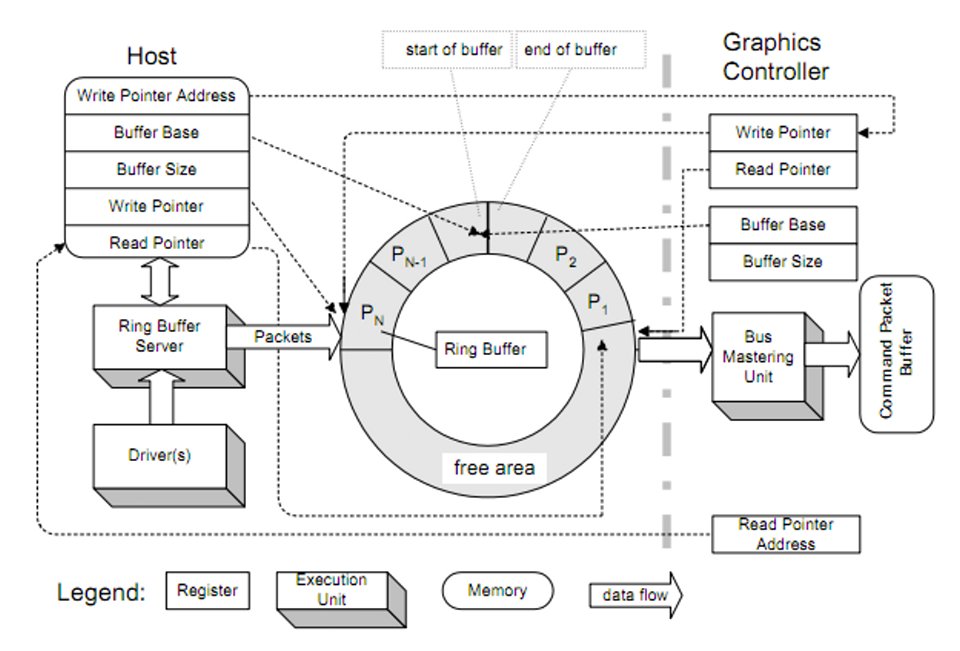
En el centro de toda GPU y como director de orquesta del Frontend se encuentra el procesador de comandos, cuyas tareas son las siguientes:
- Recibe los comandos de la CPU.
- Interpreta las instrucciones gráficas (draw, dispatch, state changes, etc.).
- Coordina el envío de trabajo a otras partes de la GPU.
- Gestiona múltiples colas de trabajo, permitiendo ejecutar tareas gráficas y de cómputo en paralelo.
En las primeras GPU, el procesador de comandos gestionaba un solo anillo para generar gráficos, es decir, una lista cerrada de comandos creados por la CPU donde al llegar a la última dirección de memoria se volvió al primero, pero a partir de DirectX 12 y Vulkan tenemos no uno, sino varios anillos funcionando en paralelo y que pueden trabajar de forma asíncrona. No obstante, no debemos ver al procesador de comandos como una pieza única y monolítica.
Los RISC Micro-Engines
Dentro del procesador de comandos de una GPU, incluida la futura UDNA, existen los llamados RISC Micro-Engines. No se trata de CPU completas, sino que son unidades de procesamiento dedicadas que se sitúan dentro de otro chip más complejo. Su trabajo es ejecutar microcódigos o microinstrucciones para tareas específicas y repetitivas. Funcionan como un microcontrolador, ya que solo tienen acceso a su memoria interna. Se diferencian de las unidades de función fija en el hecho de que son programables.
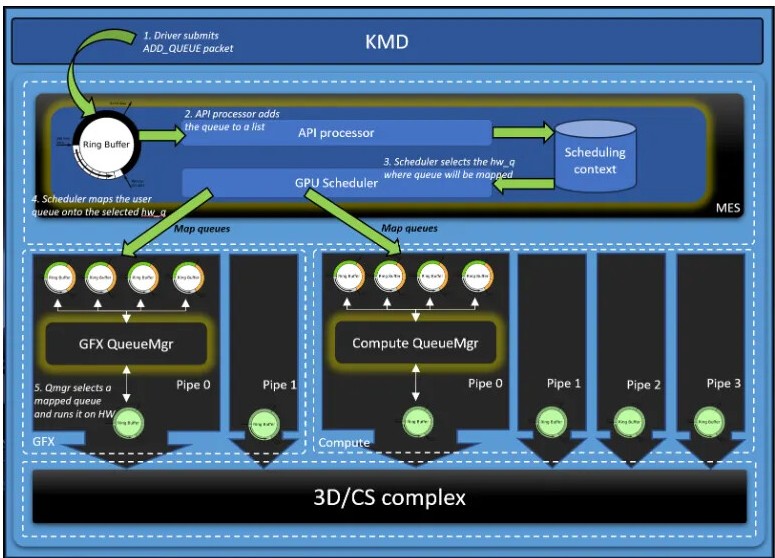
En una GPU contemporánea, el procesador de comandos puede tener varios RISC Micro-engines encargados de gestionar la captación e interpretación de datos para enviarlos luego a las Compute Units correspondientes. También se encargan de la sincronización, es decir, qué núcleos de la GPU se encuentran ocupados, cuáles no y en qué medida. Además, también tienen la capacidad de realizar tareas de decodificación de video o control de búferes.
No obstante, estos tienen una parte negativa y es que tradicionalmente han perdido sus capacidades a favor de que sea la CPU la que se encargue a través del driver de realizar tareas que son propias del procesador de comandos y los RISC Micro-Engines. Una de las filosofías detrás de UDNA es volver a tener un procesador de comandos cuyo rendimiento no dependa del driver gráfico.
¿Qué cambiará con UDNA?
La idea que parece tener AMD en UDNA en lo que al Frontend se refiere es la creación de una GPU totalmente reconfigurable y virtualizable, es por ello que vamos a ver un nuevo procesador de comandos en la nueva arquitectura, el cual reemplazará al utilizado en RDNA y será uno de los puntos más importantes de la nueva arquitectura gráfica. Tened en cuenta que, a dia de hoy, una GPU no solo son las unidades que ejecutan los programas shader, sino que un buen coordinador central es clave.
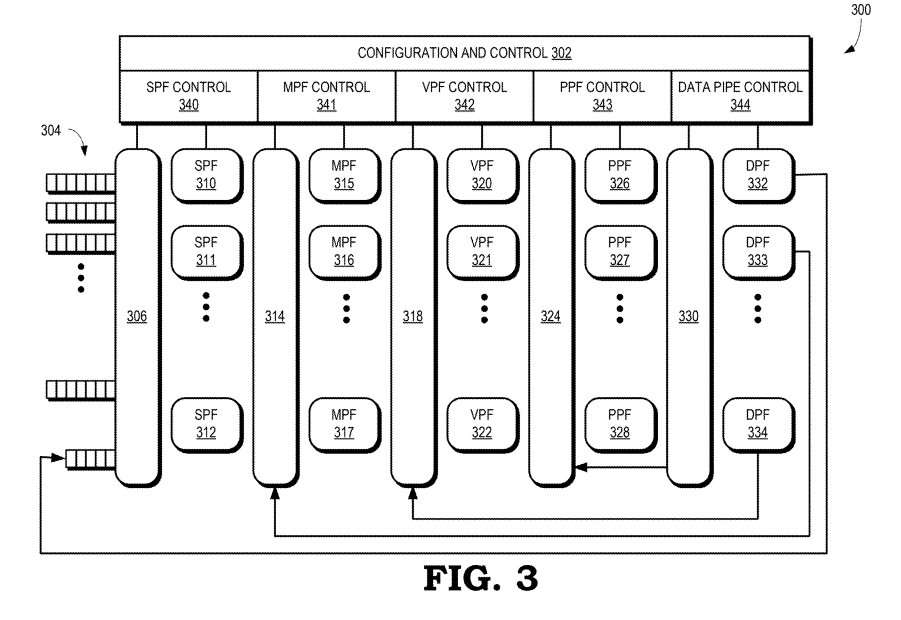
En la actualidad, la virtualización de una GPU se utiliza en entornos multiusuario en estaciones de trabajo y centros de datos, por lo que no parece algo útil en el mundo del hardware doméstico. En ese caso, se trata de soluciones que dependen de software. La diferencia aquí es que con UDNA de esto se encargará el propio procesador de comandos y los RISC Micro-Engines. Dado que estaríamos hasta hacernos viejos para explicarlo, el concepto principal aquí es el llamado Virtual Pipe Fragment o VPF. Donde el programa no tiene que verse con un pipeline gráfico fijo, sino que puede configurarlo a medida.
| Configuración | Descripción rápida |
|---|---|
| IA->VS->RS->DB | Solo cálculo de profundidad (Z-buffer). Sin color. Muy útil para sombras, Z-prepass. |
| IA->VS->RS->PS->DB | Igual que anterior, pero con píxel shader (ej. test de transparencia antes de escribir Z). |
| IA->VS->RS->PS->CB | Solo color. Útil para UI, render targets auxiliares, efectos sin profundidad. |
| IA->VS->RS->PS->DB->CB | Renderizado completo con color y profundidad. Es el pipeline estándar. |
| IA->VS->GS->RS->PS->DB->CB | Pipeline con geometry shader, útil para generación masiva de geometría (cabello, partículas). |
| IA->VS->HS->TESS->DS->RS->PS->DB->CB | Pipeline con teselación: modelado fino de superficies. |
| IA->VS->HS->TESS->DS->GS->RS->PS->DB->CB | Pipeline máximo: teselación + geometry shader + render completo. Ideal para modelos complejos y efectos especiales. |
Si las siglas no os suenan, son componentes comunes en toda GPU; en todo caso, os las desglosamos a continuación:
| Abreviatura | Unidad | Función |
|---|---|---|
| IA | Input Assembler | Ensambla datos de entrada (vértices, índices). |
| VS | Vertex Shader | Transforma vértices en el espacio 3D. |
| HS | Hull Shader | Define la subdivisión de patches para teselación. |
| TESS | Tessellator (Fixed Function) | Subdivide superficies curvas en triángulos. |
| DS | Domain Shader | Mapea puntos teselados en el espacio. |
| GS | Geometry Shader | Opera sobre primitivas completas, permite duplicación o eliminación. |
| RS | Rasterizer (Fixed Function) | Convierte primitivas en fragmentos (pixeles). |
| PS | Pixel Shader (Fragment Shader) | Calcula el color de cada fragmento. |
| DB | Depth/Stencil Buffer | Escribe y compara profundidad/stencil. |
| CB | Color Buffer | Escribe el color final de cada píxel. |
Es decir, se acabó el hecho de tener que depender de siempre las mismas etapas para generar los gráficos de un juego, que es lo que ocurría hasta el momento. La realidad es que no todos los juegos requieren todas las etapas del pipeline gráfico de DirectX 12, mientras que otros juegos determinados pueden necesitar nuevas etapas para tareas específicas que no se han definido en ninguna API estándar.
Virtualización
Las GPU virtuales suelen utilizarse en el mundo de los centros de datos, pero en el mundo del gaming su utilidad se encuentra en el Cloud Computing. Desde el momento en que tanto Sony como Microsoft ya disponen de servicios de juego en la nube basadas en el hardware de sus actuales consolas, es normal que UDNA al ser una arquitectura pensada para la siguiente generación de consolas y también para los centros de datos, pues que pueda funcionar como una GPU virtual o vGPU.

La idea es simple: los núcleos de la GPU y una cantidad concreta de recursos se subdividen entre varios clientes, los cuales pueden estar en local o en remoto, permitiendo que estos puedan utilizar una porción de la potencia de la misma. No obstante con UDNA cambiará un poco la cosa, por el hecho de que cada VPF con sus recursos acotados formará una GPU para una tarea concreta. La diferencia es que, al contrario de otras soluciones donde depende de una gestión por software de los entornos virtualizados, el procesador de comandos de UDNA será capaz de manejarlo todo ello por hardware, sin ayuda de ningún elemento externo en cuanto a hardware.
Incluso será posible hacer que los núcleos de la GPU actúen como Micro-Engines para reemplazar ciertas unidades de función fija si no tienen tareas asignadas y pueden llevar a cabo su trabajo de forma más rápida que dichas unidades, pudiéndolas desactivar a través del pipeline creado por el desarrollador para su videojuego.
El Backend de UDNA y las unidades de función fija
Mientras que el Frontend se encarga de captar, decodificar y distribuir las diferentes tareas a los núcleos de la GPU y a las unidades de función fija, encargándose también de la distribución, es aquí donde precisamente hablaremos de dichas unidades, las cuales, fuera de los Ray Accelerator Units, no van a ver una mejora respecto a las consolas de la actual generación. Es más, con el advenimiento del Machine Learning y los algoritmos de superresolución (DLSS, FSR, PSSR, XeSS, etcétera) la industria ha virado al concepto de renderizar el frame base a menor resolución y luego escalarlo por IA.

Esto sumado a que los televisores 8K no parece que vayan a tener el mismo impacto que tuvieron aquellos con televisor 4K y mucho antes los Full HD, pues parecen indicar que las tasas de relleno y texturizado que se requerirán no serán mucho más altas que las de la actual generación, al menos en apariencia. Aunque no debemos quedarnos solo en ello, hay una gran multitud de videojuegos que reproducen juegos sin problemas a una resolución de 4K a 30 FPS en modo calidad, con PS5 Pro se alcanzan los 4K 60 utilizando el PSSR como trampa para hacerlo, para la next gen lo ideal serían los 4K60 en nativo para esos juegos.
Al igual que ocurrió con el paso de PS4 Pro a PS5, donde pese al cambio de arquitectura no se aumentó la cantidad de núcleos, creemos que en el salto de PS5 Pro a PS6, esta continuará teniendo una configuración de 60 núcleos. Eso sí, a una velocidad de reloj mucho más alta. Por el contrario, un rendimiento similar deberíamos esperar de la próxima Xbox de sobremesa, la cual también se basará en la arquitectura UDNA.
¿Qué rendimiento podemos esperar de las Compute Units?
Según KeplerL2, uno de los filtradores de más prestigio se espera en lo que a rasterización (la manera clásica de renderizar gráficos en 3D) de un aumento del 20 % respecto a las actuales RDNA 4. Curiosamente, al tiempo de escribir este artículo, la gente de ComputerBase ha hecho una comparativa entre las RX 9070 (RDNA 4) y las RX 7800 de AMD (RDNA 3), donde han configurado dos tarjetas gráficas con la misma cantidad de núcleos, velocidad de reloj y velocidad de la memoria. ¿Sus conclusiones?
AMD RDNA 4 funciona, en promedio, un 20 % más rápido que su predecesor, RDNA 3, con la misma potencia de procesamiento teórica. Esto concuerda con el enorme aumento de rendimiento de la Radeon RX 9070 XT en comparación con la Radeon RX 7800 XT, a pesar de que la primera apenas ofrece más unidades de ejecución.
El rendimiento de RDNA 3 y RDNA es igual por ciclo de reloj y por núcleo, por lo que de entrada tenemos un 20% asegurado respecto al rendimiento en la actual generación de consolas. En cuanto a las palabras de KeplerL2, por lo visto hemos de añadir un 20% adicional, por lo que la cosa se queda en un 44%. Eso sí, esto es sin tener en cuenta los elementos para Machine Learning (IA) y el Ray Tracing, donde el rendimiento parece ser que se duplicará en UDNA respecto a RDNA 4.
Es decir, como siempre, la potencia no será comparable en lo que a igualdad de TFLOPS se refiere, por lo que estamos en un escenario similar al salto que hubo de GCN a RDNA. Es más, es por ello que nosotros no esperamos un aumento de núcleos en la GPU, pero sí la mejora en otros departamentos.
Duplicando la capacidad para la IA
Uno de los puntos para conseguir aumentar el rendimiento son las unidades de ejecución vectoriales. En RDNA 4 tenemos precisamente 4 tipos de unidades compartiendo el mismo conjunto de registros vectoriales. Lo cual significa que cuando una de estas unidades accede a los mismos, las otras no pueden acceder, por lo que se van turnando el acceso a los mismos. Dichas unidades son una unidad SIMD de 32 ALU de 32 bits para coma flotante, otra similar para enteros, una TLU de 8 ALU para operaciones trascendentales (raíces, logaritmos, operaciones trigonométricas, etc.) y por último, el correspondiente Array Sistólico, llamado en este caso bajo el nombre de AI Accelerator.

Sin embargo, lo que nos interesa de momento es la mejora en el AI Accelerator en UDNA, la información de la diapositiva de arriba no nos dice mucho del ratio real de operaciones por ciclo, pero si miramos en la página de AMD obtenemos la cifra en FP16/BF16, que son 1024 operaciones por ciclo, duplicando a precisión de 8 bits. Por lo que la configuración de cada AI Accelerator es de un array sistólico de 64 x 16 con soporte para SIMD sobre registros para duplicar el rendimiento en precisiones inferiores.
Pues bien, dado que en UDNA se duplicará el rendimiento en IA, aquí tenemos dos posibilidades. La primera es que los registros no se dupliquen en tamaño respecto a RDNA 4, pero que la configuración pase a ser de 64 x 32. La segunda es que sí lo hagan y pasemos a tener una posible configuración de 128 x 16 o que esta se pueda desglosar en 2 x 64 x 16. Es decir, que haya dos unidades en total por banco de registros vectoriales.
Duplicando los registros para duplicar el rendimiento
La particularidad de las GPU es que sus registros son mucho más grandes que los de una CPU, esto se debe a que para evitar accesos continuos a memoria lo que se almacena en ellos son los próximos hilos a ejecutar. En la ISA de RDNA es posible tener hasta 256 registros vectoriales (VGRP), donde, en modo de 32 componentes por ola, cada VGRP tiene un tamaño de 1024 bits. Dado que tenemos 2 unidades SIMD, esto se traduce en que puede almacenar en dichos registros hasta 16 hilos de ejecución por SIMD. El problema es que para ello serían necesarios 512 KB, pero solo existen 192 KB en el banco de registros, lo cual ya es una mejora sobre los 128 KB de RDNA 2 y RDNA 3 y los 64 KB de GCN.

No obstante, la cantidad de unidades SIMD de GCN a RDNA, simple y llanamente debido a que el tiempo de ejecución por ola aumentó, al menos en el modo de 32 componentes por ola, AMD se vio forzada a duplicar el tamaño para que los núcleos de la GPU no se quedaran sin trabajo por hacer. La mejora de 192 KB en RDNA 4 fue en el mismo sentido. Pero nuestra idea aquí de duplicar la cantidad de registros, no va en ese sentido. Va en el sentido de duplicar la cantidad de unidades conectadas por VGRP y hacer posible la actualización de 32 componentes máximos hasta 64 componentes.
Nuestro concepto es claro: el uso de memoria GDDR7 permite duplicar el ancho de banda externo y esperamos al mismo tiempo que se duplique el ancho de banda interno para compensar. Permitiendo mover el doble de datos y con ello poder llenar registros, memorias locales y cachés igual de grandes en la misma cantidad de tiempo.
De SIMD a SIMT y virtualización
En la entrada sobre PlayStation 6, comentamos que AMD, de cara a UDNA, debería dar el salto de SIMD a SIMT, al menos en lo que respecta a las unidades vectoriales convencionales. La idea es permitir que todas las ALU estén activas, redirigiendo aquellas que no se encuentran en uso hacia otras tareas. Y es que no siempre las olas que llegan utilizan la capacidad máxima de componentes, lo que deja inactivas varias de las ALU disponibles.
- El simple hecho de pasar de SIMD a SIMT permite asignar dinámicamente estas ALU inactivas a otros hilos u operaciones. En particular, esta transición haría posible combinar operaciones con enteros y en coma flotante dentro de una misma ola, aunque para ello el planificador del núcleo debería ser capaz de crear y organizar subconjuntos de hilos con perfiles de ejecución diferenciados.
- No obstante, este cambio no afectaría ni al AI Accelerator Array ni a las 8 unidades TLU, ya que se trata de bloques funcionales especializados que operan con arquitecturas distintas. La intención general es mejorar el rendimiento, maximizando la ocupación de los recursos disponibles.
Ahora bien, teniendo en cuenta que UDNA soportará virtualización por hardware, cabe preguntarse si sería posible reutilizar las unidades no activas dentro de una Compute Unit para instanciar una segunda ejecución en paralelo. Aunque esto pueda parecer rizar el rizo, la idea de Compute Units virtuales no nos parece nada descabellada. Para ello, sin embargo, sería imprescindible que cada Compute Unit incorporase un planificador interno más avanzado que el disponible hasta ahora.
Este es, precisamente, uno de los motivos por los cuales pensamos que el número total de núcleos o Compute Units no aumentará significativamente de RDNA a UDNA, principalmente debido al aumento de complejidad que implicaría introducir estas nuevas capacidades internas.
La ventaja real
Actualmente, los juegos para Xbox Series y PS5 utilizan olas de 32 componentes, pues esta configuración es la más eficiente en las arquitecturas RDNA actuales. Sin embargo, si en UDNA se duplica el tamaño del VGRP y la cantidad de slots por ola, pasando a unidades de 64 elementos, el mapeo directo de olas de 32 componentes resultaría en una ocupación del 50%.

Nuestra propuesta es que esta mitad restante sea aprovechada por el array sistólico, permitiendo la ejecución en paralelo de hilos destinados tanto a tareas de inteligencia artificial como a gráficos convencionales. De esta forma, la duplicación del VGRP y los slots no solo aumenta la capacidad de procesamiento, sino que también posibilita un uso simultáneo y eficiente de recursos para cargas heterogéneas, algo clave para el futuro de las arquitecturas orientadas a IA y gráficos híbridos.
Por supuesto, cuando sea necesario, los 64 componentes podrían emplearse íntegramente para IA o para ejecución vectorial tradicional. La idea es que los algoritmos de IA, tan en auge, no se limiten a actuar solo en los momentos de tiempo libre de la GPU, sino que puedan funcionar continuamente siempre que sea necesario. Lo que permite el uso de nuevos algoritmos gráficos que se aprovechan del Deep Learning que de otra forma no serían posibles.
Mejoras en Ray Tracing
Ahora que hemos llegado a este punto, vamos a explicar una de las ventajas que supone el uso de la IA en gráficos más allá de lo visto hasta el momento. Para sostener nuestra visión nos vamos a basar en una patente reciente de AMD, titulada NEURAL NETWORK-BASED RAY TRACING que se basa en el concepto de usar redes neurales para almacenar la información de la escena para el Ray Tracing llamadas NIF, en vez de utilizar estructuras de datos como árboles BVH. No lo comentamos en la entrada de PlayStation 6 por el hecho de que se nos pasó por completo.
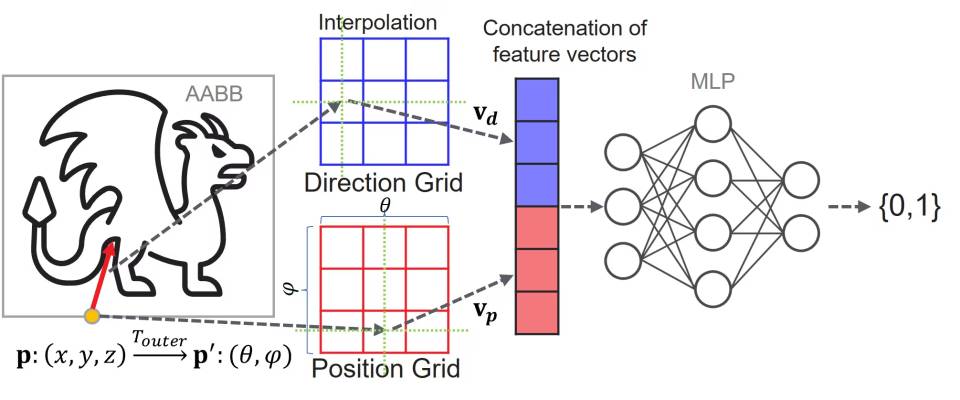
A pesar de años de mejoras, el trazado de rayos basado en BVH (Bounding Volume Hierarchies) sigue siendo un reto para el hardware actual, especialmente en arquitecturas SIMT como las GPU. La exploración del BVH es inherentemente irregular: provoca divergencias en el flujo de control y accesos a memoria impredecibles. Esto dificulta aprovechar al máximo la capacidad de paralelismo de las GPU, que funcionan mejor con cargas uniformes y paralelas. Por eso, aunque se añada hardware especializado para acelerar el trazado de rayos, la exploración del BVH sigue siendo un cuello de botella en renderizados de alta calidad.
Por otro lado, las redes neuronales, especialmente las completamente conectadas, presentan un patrón computacional mucho más regular y predecible, dominado por multiplicaciones de matrices densas. Este tipo de cálculo encaja perfectamente con las arquitecturas SIMT de las GPU, lo que hace que la inferencia sea muy eficiente. Este contraste entre la irregularidad de la exploración BVH y la regularidad de las redes neuronales plantea una pregunta interesante: ¿podríamos reemplazar la exploración del BVH en el trazado de rayos con una red neuronal para sacar más provecho del hardware de las GPU?
No obstante, requiere entrenamiento
Al basarse en una red neural, los NIF tienen una limitación importante, y es que requieren ser entrenados previamente. Esto significa que, al igual que ocurre con técnicas como el DLSS, el sistema tendrá que renderizar primero los juegos de forma convencional, utilizando los BVH, para aprender a generar el NIF y prescindir de ellos llegado el momento. Por lo que en realidad, pese al uso de esta técnica, esta no supondrá la eliminación completa del uso de las estructuras BVH en juegos futuros.

La otra limitación viene cuando varios rayos coinciden en un mismo punto en la pantalla, lo que termina por crear errores dentro de la red neural. La solución viene por un proceso de voxelización de la escena, una idea que se planteó en los inicios del Ray Tracing a tiempo real, pero que se abandonó a favor del uso de los árboles BVH. Pensad que los vóxeles son píxeles 3D, donde en vez de tener dos coordenadas, tienen tres, lo cual sirve para aumentar el número de potenciales puntos y reducir la cantidad de potenciales errores a la hora de usar los NIF.