Una de las particularidades de la actual generación de consolas es cómo funciona el acceso a la memoria, el cual es cuanto menos peculiar y hereda todos los problemas de las configuraciones típicas de PC, pero encima aumentados. No obstante, no veréis a ningún medio hablar de ello, ya que no tienen relación con ninguna palabra clave de marketing y nadie quiere hablar de las vergüenzas de sus productos. Es por ello que hemos preparado este artículo, para que podáis ver cuál es el mayor cuello de botella en consolas a día de hoy.
NUMA, UMA y Pseudo-UMA
Independientemente de la capacidad de trabajo de cada uno de sus componentes, los PC a día de hoy continúan teniendo la misma organización de memoria, la cual es del tipo NUMA. Esto significa que la memoria está organizada de forma no uniforme (Non-Uniform Memory Access, NUMA). En un sistema de este tipo, el sistema no solo está compuesto por un nodo central, CPU, sino muchos nodos (tarjetas de expansión) donde cada uno de ellos tiene su propia memoria local o, si la interfaz lo permite, acceder a la memoria del sistema. Pero en el caso de los nodos no centrales, acceder a la memoria del sistema o central, supone menos rendimiento debido a la latencia adicional que implica atravesar el bus o interconexión entre nodos.

En el otro extremo tenemos UMA, utilizada a día de hoy, sobre todo en teléfonos móviles y arquitecturas derivadas, como actualmente la que usa Apple. En este caso tenemos un solo pozo de memoria físico con un direccionamiento único y un acceso compartido. Lo que supone una mayor contención en el acceso a los datos. Dicho de otra forma, no importa qué núcleo acceda a qué porción de memoria: la latencia y el ancho de banda son uniformes para todos. Esto permite comunicar los diferentes componentes sin tener que usar buses alternativos para realizar transferencias explícitas de un espacio de memoria a otro.
Pues bien, en el cuello de botella en consolas, lo que incluye a la Steam Deck se emplea Pseudo-UMA. Es que, a nivel físico, la memoria está unificada, pero el direccionamiento no. Es decir, en el ámbito de la programación se comportan como un sistema NUMA, para facilitar la portabilidad desde el PC. Lo cual tiene sentido solo de cara a los costes, pero no del rendimiento.
Todo hubiese sido distinto
Una vez que hemos entendido que las consolas tienen una organización de memoria pseudo-UMA, hemos de retroceder a la generación anterior, no de tarjetas gráficas, sino de consolas, pero no a las máquinas en sí, sino a una propuesta que la propia AMD colocó encima de la mesa. Para ello tenemos que recordar una propuesta llamada HSA, la cual fue una iniciativa para unificar CPU y GPU en un entorno de cómputo totalmente coherente, es decir, que CPU y GPU vieran el mismo espacio o direccionamiento de memoria. En la iniciativa no estaba solo la propia AMD, sino que se sumaron, al menos sobre el papel, otras empresas como ARM, Qualcomm, Samsung, MediaTek, Imagination Technologies y Texas Instruments.
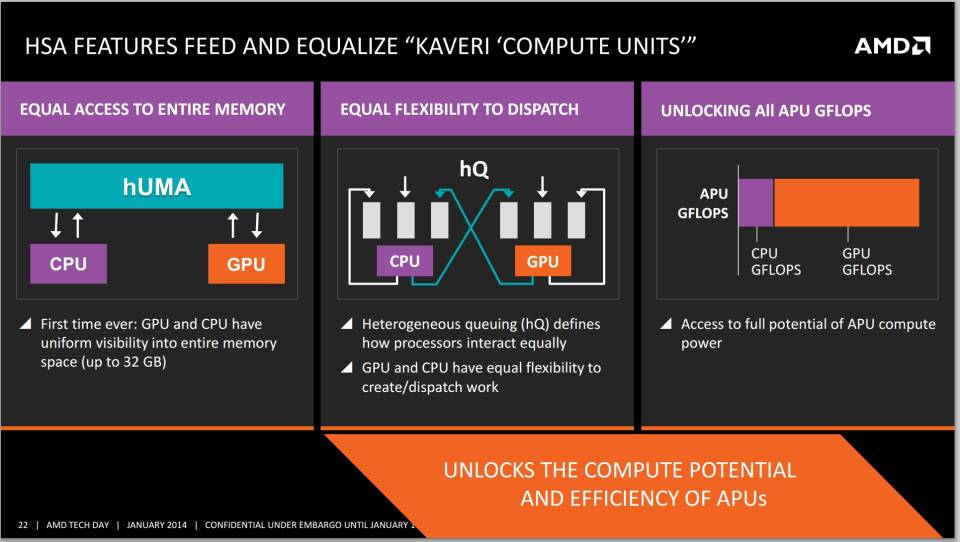
¿Qué ocurrió? Entre 2017 y principios de 2018, la propia AMD D traicionó por completo la hoja de ruta para el HSA ideado en ese sentido con los primeros Ryzen, abandonando con ello los mecanismos de coherencia de memoria, los cuales ya había conseguido implementar al 100% en Carrizo. Esto hizo que los SoC de AMD para PC y consolas, los que integran una GPU en su interior, continuaran teniendo de cara al futuro un direccionamiento de memoria no unificado y diferenciado en partes. Sin embargo, la cosa se agrava mucho más cuando tenemos en cuenta la forma en la que acceden a memoria los diferentes Ryzen, independientemente del chip que hablemos.
¿Qué consecuencias ha tenido esto en la actual generación?
Sencillo, por ejemplo, nos encontramos que en las Xbox Series (y sospechamos que también en PS5 y PS5 Pro) tanto la GPU como la CPU no pueden acceder a toda la memoria de forma directa, teniendo que depender de mecanismos DMA de copia de datos y búferes intermedios que son una complicación adicional para los desarrolladores a gestionar. Lo ideal sería un espacio de memoria unificado desde el punto de vista del direccionamiento, ya que, aparte de dar más flexibilidad a la hora de asignar las cantidades de memoria, viene con una serie de ventajas en comparación con la solución pseudo-UMA actual.
| Característica | Memoria Unificada (UMA) | Memoria Separada (NUMA y Pseudo-UMA) |
|---|---|---|
| Acceso a la memoria | CPU, GPU y otros usan la misma memoria física | CPU y GPU tienen memorias distintas (RAM y VRAM) |
| Copiado de datos | No es necesario duplicar datos | Requiere copiar datos entre RAM y VRAM |
| Rendimiento conjunto CPU-GPU | Más eficiente y rápido | Más lento por la transferencia de datos |
| Consumo energético | Más bajo | Más alto (por duplicación y transferencias) |
| Uso total de memoria | Más eficiente, memoria compartida | Menos eficiente, memoria duplicada |
| Latencia | Baja | Más alta por transferencia entre memorias |
| Desarrollo y programación | Más simple, sin gestión explícita de copias | Más complejo, requiere sincronización manual |
| Coherencia de datos | Inmediata, datos actualizados en todo momento | Posible desincronización entre CPU y GPU |
Si bien una configuración al estilo PC donde CPU y GPU tienen pozos de memoria separados da más rendimiento, debido a la menor competencia para acceder a los datos, no es ningún secreto que en consolas se ha optado siempre por una configuración aparentemente UMA para simplificar los costes. El hecho de tener una configuración pseudo-UMA trae consigo todos los problemas de ambos planteamientos y ninguna de las ventajas.
En cambio, con un direccionamiento totalmente unificado, los desarrolladores no se verían obligados a implementar soluciones adicionales para sincronizar y transferir datos entre CPU y GPU. Es decir, se reduciría la complejidad y el resto de errores que pueden terminar por alargar el tiempo de desarrollo del videojuego por la corrección de errores y el impacto negativo en el rendimiento. Es decir, puro concepto KISS o de mantener las cosas lo más simple posible, especialmente de cara a la programación. Por desgracia, se carga en los hombros de los desarrolladores tareas que no deberían ocurrir si se hubiese realizado un buen diseño.
¿Por qué no se ha hecho?
Hay dos formas de conseguir la coherencia de memoria total entre CPU y GPU.
- Añadir un nivel de memoria caché adicional cercano al controlador de memoria y con mayor capacidad que en los niveles de caché más altos de CPU y GPU. La condición es que la latencia entre memoria y la CPU, la cual es más sensible en ese aspecto que la GPU, lo permita, ya que no tiene sentido que la suma en el tiempo de recorrido de los diferentes niveles de caché sea más alta que el acceso directo a la RAM.
- Permitirle a la GPU «esnifar» el contenido de la memoria caché de la CPU para saber los cambios en cada una de las direcciones de memoria. Este método fue el utilizado en Carrizo por parte de AMD, pero descartado mucho más tarde cuando dieron el salto a las arquitectura Zen con Ryzen.
¿El problema de ambos planteamientos? Simplemente, requieren un chip más complejo, ergo, con más transistores y, por lo tanto, más caro. Pensad que en una consola de videojuegos el presupuesto es limitado y hay una preferencia a la hora de implementar ciertas tecnologías o soluciones.
El cuello de botella en consolas es culpa de AMD
Ahora bien, el diseño de los AMD Ryzen tiene un problema, especialmente si hablamos del acceso a la RAM por parte de los clientes de la CPU. Se trata de algo común de todos los chips de la gama Ryzen, desde los primeros en salir, hasta los actuales. Y en cualquier modelo, tanto los tipo SoC que se encuentran en un solo chip con una GPU integrada, así como aquellos que tienen una configuración por chiplets y disgregada. Pues bien, en todos ellos, el controlador de memoria, que es la pieza que le permite a la CPU acceder a la memoria RAM, que es el Unified Memory Controller.
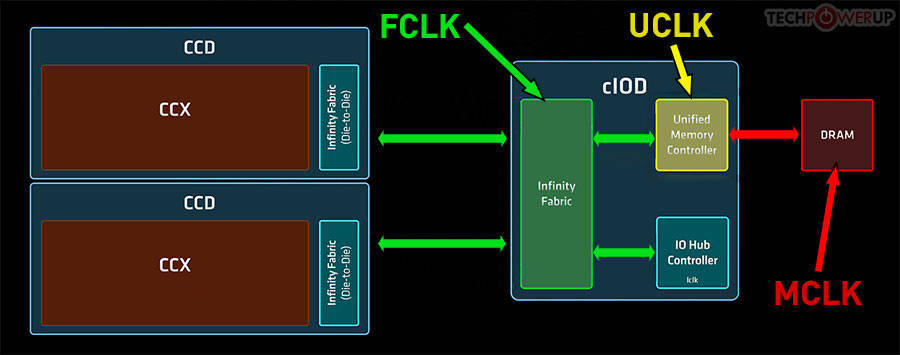
Pues bien, para sincronizarse con la RAM del sistema, este controlador funciona a la Memclk de la memoria RAM conectada al mismo. En una DDR convencional, la memclk es la mitad de su velocidad de transferencia, por otro lado, puede manejar 256 bits por ciclo de reloj. No obstante, con la GDDR6 ocurre algo único y es que el memclk es 1/8 de su velocidad de transferencia. Así pues, en las versiones estándar de las consolas, las cuales funcionan a 14 Gbps, el memclk de la RAM es de 1.75 GHz, siendo más alta en PS5 Pro que es de 2.25 GHz. ¿La consecuencia? Pues que la CPU y sus clientes acceden a un cho de banda más bajo, tampoco es que lo necesiten, pero no deja de ser un cuello de botella en las consolas.
El caso concreto de las consolas
Dado que la GDDR6 usa 2 canales de memoria por chip, si la GPU accede a ellos, le permite tener todo el ancho de banda posible a la misma. En cambio, si la CPU también accede, se le asigna uno de los dos canales, reduciendo con ello el ancho de banda total del sistema. Dado que las GPU son dependientes en rendimiento del caudal de datos. Tened en cuenta que en PC, al tener memoria propia, tienen acceso a todo el caudal de datos. Esto se traduce en una bajada general del rendimiento gráfico, a la que hay que sumarle un peor rendimiento de la CPU respecto al PC debido a una mayor latencia.
| Aspecto técnico | Qué ocurre cuando hay menos ancho de banda | Efecto visible en el juego |
|---|---|---|
| Uso de núcleos de GPU | Las unidades de ejecución (shaders) quedan inactivas esperando datos | Bajada general de FPS |
| Latencia interna | Mayor tiempo en acceder a texturas, vértices o buffers → aumento de latencia en la tubería de render | Stuttering, microtirones |
| Compresión/calidad de recursos | Se deben usar texturas, modelos o sombras más comprimidos para reducir el tráfico de memoria | Gráficos más borrosos o simples |
| Acceso a datos temporales | La GPU no puede almacenar ni recuperar eficientemente datos intermedios como reconstrucción temporal, buffers de iluminación o profundidad | Artefactos visuales en reconstrucción (ghosting, fallos en TAA/FSR) |
| Throughput total de la GPU | Disminuye el rendimiento teórico efectivo (menos operaciones por segundo), ya que no puede alimentar su pipeline al ritmo necesario | Reducción de fluidez general, FPS inestables |
| Interferencia CPU-GPU | La CPU compite por el mismo ancho de banda → acceso fragmentado o limitado para la GPU | Bajadas de rendimiento al cargar datos, pop-in |
| Gestión térmica o energética | El sistema puede reducir frecuencia de GPU o reorganizar prioridades internas cuando hay congestión en el acceso a RAM | Disminución temporal de calidad visual o framerate |
| Carga de mundo o streaming | Limitación en la velocidad de carga de datos desde disco a RAM y RAM a GPU | Texturas borrosas, geometría que aparece tarde |
Cuando una GPU no puede tener el ancho de banda ideal para funcionar, pierde rendimiento. Hablamos de un procesador que funciona en paralelo y necesita alimentar sus decenas, cientos e incluso miles de unidades con grandes cantidades de datos, por lo que un recorte en el ancho de banda tiene consecuencias nefastas en el rendimiento de los juegos, no solo en la tasa de FPS y la resolución, sino también en otros elementos. Por lo que los juegos han de diseñarse teniendo en cuenta este cuello de botella en consolas.
¿Cómo está el panorama de cara a la siguiente generación?
El uso de la memoria GDDR7 cambia por completo las reglas del juego, ya que otorga el doble de ancho de banda que la GDDR6 e incluso más. Sin embargo, trae consigo una mayor latencia y de cara a la CPU, los ingenieros deberán valorar si añaden soluciones para paliar eso. Como es el caso de cachés más grandes y/o niveles adicionales. No obstante, lo importante aquí de nuevo es la memclk, que en el caso de la GDDR7 a 28 Gbps sería de 1.75 GHz.
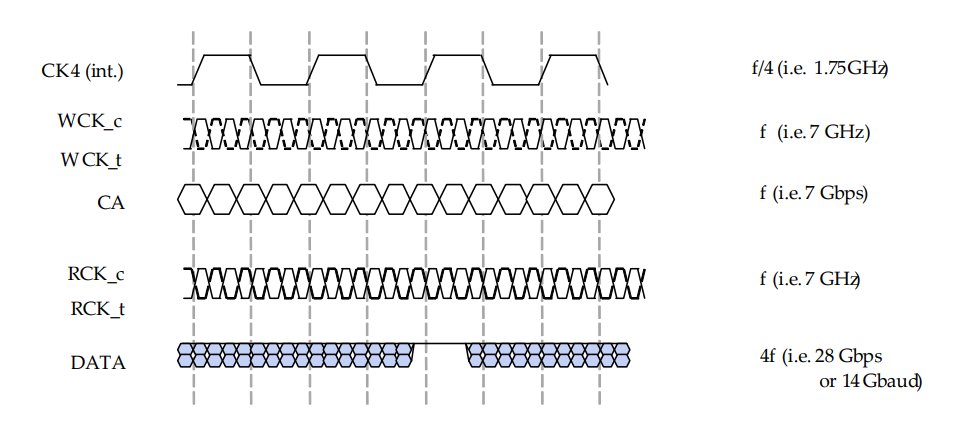
La segunda diferencia es que, mientras la GDDR6 opera con 2 canales de 16 bits por chip de memoria, la GDDR7 lo hace con 4 canales de 8 bits. Por lo que en teoría puede gestionar hasta 4 dispositivos accediendo a la misma al mismo tiempo, dándoles a cada uno de ellos el mismo ancho de banda que un canal GDDR6. Esto sería perfecto si no fuese por el problema del UMC en los Ryzen que se repetiría de nuevo, por lo que volveríamos a tener el mismo cuello de botella en consolas.
¿Es la PS5 Pro una antesala a lo que nos podemos esperar en el futuro?
Al contrario de lo que ocurre en el modelo estándar de PS5, el SoC de PS5 Pro no solo tiene acceso a la GDDR6, sino también a 2 GB de memoria DDR5. A dicha memoria no accede la GPU, ya que se encuentra físicamente separada y es de uso exclusivo para la CPU con la que tiene contacto directo. Esto, en cuanto al espacio, le da 2 GB adicionales de la GDDR 6 que se pueden asignar a la GPU; en el ámbito de la CPU, le otorga una memoria de menos latencia. Dicho de otra forma, esto reduce la cantidad de operaciones que realiza la CPU en memoria y que pueden ser un impacto para la GPU.

Esto se puede hacer por el hecho de que PS5 Pro desplaza el espacio de memoria exclusivo del sistema operativo a dicha DDR5, ya que por motivos de seguridad no se le va a dejar jamás a la GPU acceder a ese espacio de memoria. Por lo que tiene sentido separarlo, porque esto reduce el cuello de botella en consolas al permitir que las llamadas a las rutinas del sistema no compitan por el acceso a memoria a la GDDR6. Por desgracia, no soluciona el problema al completo, dado que muchas operaciones requieren que la GPU acceda al espacio de memoria de la CPU para la realización de ciertas operaciones conjuntas. Sin embargo, se trata de una pequeña ayuda para paliar el problema, pero no una solución completa.
En realidad, podríamos especular sobre cuáles pueden ser las soluciones para paliar este problema, quizás nunca se resuelva y sea algo con lo que los desarrolladores deberán aprender a lidiar.