Si bien ARM ganó hace tiempo la guerra de las arquitecturas RISC, en los años 80 y 90 el nombre de MIPS significaba una leyenda, desde las potentes estaciones de Silicon Graphics hasta históricas consolas de videojuegos como las dos primeras PlayStation o Nintendo 64. Todas ellas fueron máquinas con un microprocesador MIPS. ¿Pero cuáles son sus particulares, historia y arquitectura? Sigue leyendo para descubrirlo.
El origen de las CPU MIPS
Todo comenzó en 1981, cuando un equipo de investigación liderado por John L. Hennessy en la Universidad de Stanford se propuso demostrar algo que entonces sonaba casi provocador: que un procesador con menos instrucciones, diseñadas desde cero para la segmentación, podía superar en rendimiento a las arquitecturas establecidas de la época. El proyecto recibió el nombre de MIPS, acrónimo de Microprocessor without Interlocked Pipeline Stages. Lo que se traduce como microprocesador sin enclavamientos entre las etapas del pipeline.

Los enclavamientos no son más que mecanismos que detectan dependencias entre instrucciones y pausan la ejecución cuando ocurren; implementarlos era un gasto enorme en circuitería y un lastre de cara a aumentar la velocidad de reloj. Por lo que Hennessy apostó por trasladar dicha responsabilidad al compilador, cuyo trabajo sería el de ordenar las instrucciones de tal forma que los riesgos se evitasen en lo posible. ¿La ventaja de ello? El tener menos lógica de control se traducía en un diseño más simple, un chip más pequeño y una frecuencia de reloj más alta.
Convencido de su idea, Hennessy empezó a diseñar en el laboratorio de la Universidad de Stanford el primer microprocesador con arquitectura MIPS, el cual le llevó a fundar MIPS Computer Systems y abandonar su posición de docente. Había nacido una de las familias de microprocesadores RISC más importantes de la historia.
Su impacto en la industria y el mercado
Los microprocesadores con set de instrucciones MIPS en sus diferentes evoluciones se idearon inicialmente para el mercado de las estaciones de trabajo, siendo adoptados por un gigante por aquellos tiempos como Digital Equipment Corporation, famosa por sus miniordenadores PDP y VAX, quienes gracias al R2000 primero y al R3000 después terminaron entrando en el mundo de las estaciones de trabajo. Todo ello sin olvidarnos de la otra empresa importante nacida del campus de Stanford, Silicon Graphics, quienes también adoptaron la familia MIPS, llegando a comprar con el tiempo a MIPS Computer Systems, convirtiéndola en 1991 en una de sus subsidiarias, MIPS Technologies.
Claro está que, para el público de a pie, lo importante es lo que supuso en el mundo de los videojuegos: consolas como la PlayStation original, PlayStation 2 y PlayStation Portable usaron CPU con set de registros e instrucciones MIPS. Por otro lado, tampoco debemos dejarnos la Nintendo 64. Se puede decir que MIPS tenía por aquel entonces la misma importancia que ARM a día de hoy, ya que no solo se encontraba en las consolas más populares y en las estaciones de trabajo, sino también en los routers de la popular marca CISCO, los cuales tuvieron un boom enorme con el nacimiento de internet.
El MIPS R2000
La empresa presentó su primer diseño, el R2000, en 1985 y lo lanzó en enero de 1986. Fue la primera CPU RISC vendida comercialmente, pese a no ser la primera en ser desarrollada, y la primera implementación en forma de un producto real de todo lo que John Hennessy había teorizado. Si bien fue contemporáneo al 80386 de Intel y al Motorola 68020, el R2000 apuntó a un mercado distinto, el de las estaciones de trabajo de alto rendimiento, pero terminó siendo una influencia para el resto de la industria.

El R2000 se lanzó en tres frecuencias distintas: 8.3, 12.5 y 15 MHz. Su rendimiento alcanzaba los 8 MIPS en su versión a 12.5 MHz, lo que lo situaba en un rendimiento cuatro veces superior al del Motorola 68020, que alcanzaba los 2 MIPS a 14 MHz, por lo que ya desde sus inicios fue del interés de varias empresas importantes. Digital Equipment Corporation lo adoptó para sus estaciones de trabajo DECstation 2100 en su transición desde sus minicomputadoras PDP y VAX, pero la adopción más famosa fue la de Silicon Graphics, quienes descartaron por completo el uso de las CPU basadas en el Motorola 680×0 para adoptar el R2000 y posteriormente el R3000 en sus IRIS 4D.
No obstante, MIPS Computer Systems no disponía de fábricas propias y dejaba dicho trabajo a terceros como LSI Logic e IFT. Esta decisión de separar el diseño de la fabricación fue bastante vanguardista para la época y anticipaba el modelo fabless que hoy domina la industria de los semiconductores.
Registros
El R2000 disponía de un banco de 32 registros de uso general, cada uno de 32 bits. No es un número arbitrario: con 5 bits se pueden direccionar exactamente 32 posiciones, que es justamente el espacio que el formato de instrucción reserva para especificar un registro. La arquitectura y la codificación se diseñaron juntas desde el principio, sin ninguna concesión.

Hay que aclarar que, pese a lo que veis en la tabla de arriba, a diferencia de la arquitectura x86 de Intel, donde los registros tienen nombres y propósitos fijos grabados en el hardware, en el R2000 los 32 registros son funcionalmente idénticos desde el punto de vista del silicio. Es el compilador, o el programador en ensamblador, quien por convención asigna roles a cada uno. La única excepción real es el registro 0, que está cableado a cero y siempre devuelve ese valor independientemente de lo que se intente escribir en él. Tener un cero permanente disponible como operando simplifica enormemente la codificación de operaciones comunes como inicializar un registro, negar un valor o comparar con cero, sin necesidad de instrucciones específicas para ello.
El R2000, además de los 32 registros de propósito general, incluía un contador de programa de 32 bits, un registro de estado interno del pipeline y dos registros especiales llamados HI y LO. Estos últimos merecen una nota especial: ya que la multiplicación de dos valores de 32 bits puede dar un resultado de hasta 64 bits, el R2000 guardaba la mitad alta del producto en HI y la mitad baja en LO. También ocurría lo mismo con el cociente y el resto de una división. Para acceder a estos registros se necesitaban instrucciones específicas que mantenían limpio el formato de instrucción sin necesidad de campos adicionales.
Formato de instrucciones
Al disponer de un set de instrucciones tipo RISC, las CPU MIPS hacen uso de instrucciones de tamaño fijo (32 bits) donde los 6 primeros bits corresponden al opcode, lo que nos indica que el tamaño del set de instrucciones es de 64 en total. Al menos durante la primera generación conocida como MIPS I, que abarcó dos generaciones de la familia: R2000 y R3000. Si bien el tamaño fijo puede parecer una restricción, es clave de cara a conseguir la captación y la decodificación de instrucciones en un solo ciclo de reloj. Todo ello gracias a que la etapa de captación siempre sabe cuántos bits tiene que leer, y la etapa de decodificación siempre trabaja con el mismo ancho de palabra.
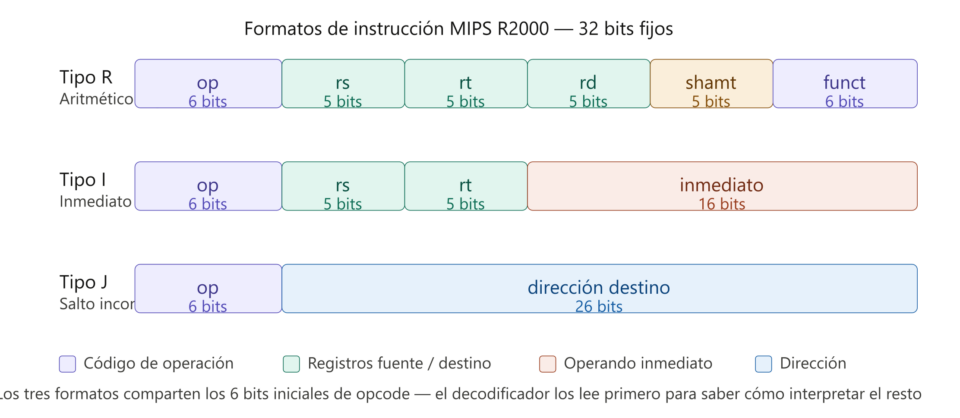
Dentro de esos 32 bits, tanto el R2000 como el R3000 definen tres formatos distintos según el tipo de operación. En todos ellos, el decodificador es el encargado de leer los primeros 6 bits y saber lo que debe hacer con el resto de los datos. Esto simplifica enormemente la lógica de decodificación y contribuye a que la etapa ID pueda completarse en un solo ciclo de reloj.
Interfaz de coprocesadores
Una particularidad del MIPS R2000, y de sus sucesores, era su interfaz de coprocesadores, la cual le permitía comunicarse directamente con una serie de chips de apoyo sin tener que pasar por la RAM para ello. Esto terminaría siendo una de las características definitorias de las CPU con set de instrucciones MIPS en un futuro, ya que permitía crear variaciones a medida con funcionalidades extra que iban más allá de la especificación básica del chip. Sin embargo, el COP0 (System Control Processor) y el COP1 (Unidad de coma flotante) no eran de libre elección, encontrándose el primero dentro del mismo R2000 y el segundo en un chip aparte.
En el caso de COP2 y COP3, habitualmente estos coprocesadores eran de libre elección para los arquitectos de cada sistema e incluso daban la capacidad de crear chips personalizados y a medida de las necesidades del hardware. La interfaz estaba pensada con suficiente generalidad como para que cualquier fabricante pudiera diseñar su propio coprocesador especializado y conectarlo al bus. Un ejemplo histórico de ello son las unidades MDEC y GTE de la primera PlayStation, así como las VU de PlayStation 2.
El R2010, la unidad de coma flotante
El R2010 en realidad funcionaba casi como una CPU al completo, con la diferencia de que se encargaba de ejecutar las instrucciones aritméticas en coma flotante. Sin embargo, está subordinado al R2000 desde el momento en que comparte con este el acceso a la RAM (direccionamiento y bus de datos). En sistemas de alta gama era normal colocar hasta tres R2010 en los respectivos puertos para coprocesadores, lo cual hizo al R2000 una pieza imbatible en el mundo de la computación científica de alto rendimiento.

Disponía de su propio set de registros, también 32 en total, pero de 64 bits de tamaño, y su particularidad era que su pipeline era de 7 etapas, a excepción de las operaciones a memoria, dada la complejidad de algunas de las instrucciones que podía ejecutar, las cuales requerían una subdivisión aún más grande en la etapa de ejecución.
System Control Processor
El COP0 era el único coprocesador definido dentro de la arquitectura que no podía ser modificado por terceros, ya que sin él el R2000 no podía actuar como una CPU completa para una estación de trabajo. Su función era gestionar todo lo relacionado con el funcionamiento del sistema: las excepciones, las interrupciones, la gestión de memoria virtual y la traducción de direcciones. En la práctica, era la capa que separaba el hardware del sistema operativo, y sin él no habría sido posible ejecutar Unix sobre el R2000.

Se trata del único coprocesador que no es externo por un motivo muy simple: para que la segmentación de 5 etapas funcionase a un ciclo por instrucción, la traducción de direcciones virtuales a físicas de la memoria (tarea de la MMU) tenía que ocurrir en una fracción de ciclo dentro de la propia CPU. Si el COP0 hubiese estado en un chip externo, los tiempos de propagación eléctrica por la placa base habrían destrozado el rendimiento del pipeline.
El R2020 y el cuello de botella con la memoria
Para poder alcanzar el rendimiento esperado, el R2000 y sus coprocesadores necesitaban la ayuda de un mecanismo compuesto por cuatro chips simétricos que creaban un pipeline ordenado, que se encargaban cada uno de ellos de manejar una operación de escritura en memoria. Esto se hacía por el hecho de que, por aquel entonces, si la RAM era demasiado lenta, el hecho de tener que sincronizar con ella suponía una pérdida enorme de ciclos de reloj para la CPU, por lo que la opción en el R2000 fue hacer que otro chip, el R2020, se encargase de manejar las escrituras a memoria, dejando libre el propio R2000 para seguir trabajando.
A todo ello había un problema añadido: cada vez que el R2000 ejecutaba una instrucción que requería escribir en memoria, dicha información se actualizaba en dos memorias: la memoria caché de datos y la RAM, pero mientras que la primera funcionaba a la misma velocidad de reloj que el microprocesador, la RAM externa tenía un tiempo más lento y, si tenía que esperar que la RAM confirmara cada operación de escritura, entonces la caché no serviría de nada y dejaría a la CPU parada varios ciclos de reloj sin hacer nada, perjudicando seriamente el rendimiento.
¿Qué es la segmentación o pipelining?
La mayor aportación de la arquitectura MIPS al mundo fue el llamado pipelining o segmentación. Tal es así que a día de hoy todo chip con la capacidad de procesar instrucciones es un diseño segmentado. Para entender su funcionamiento, nos hemos de imaginar una línea de ensamblaje donde el proceso de fabricar un nuevo producto se divide en tareas más pequeñas que ocurren secuencialmente y en una pequeña fracción del tiempo total. Cada una de las tareas pequeñas es una etapa y están conectadas en un cauce ordenado para cada instrucción. Dado que las etapas están conectadas entre sí y son sucesivas una detrás de otra, por lo general, cada una de ellas dura un ciclo de reloj.
Así pues, la segmentación lo que hace es explotar el paralelismo entre las diferentes etapas que ocurren de forma secuencial. En el MIPS clásico, la ejecución de una instrucción se divide en cinco etapas fundamentales:
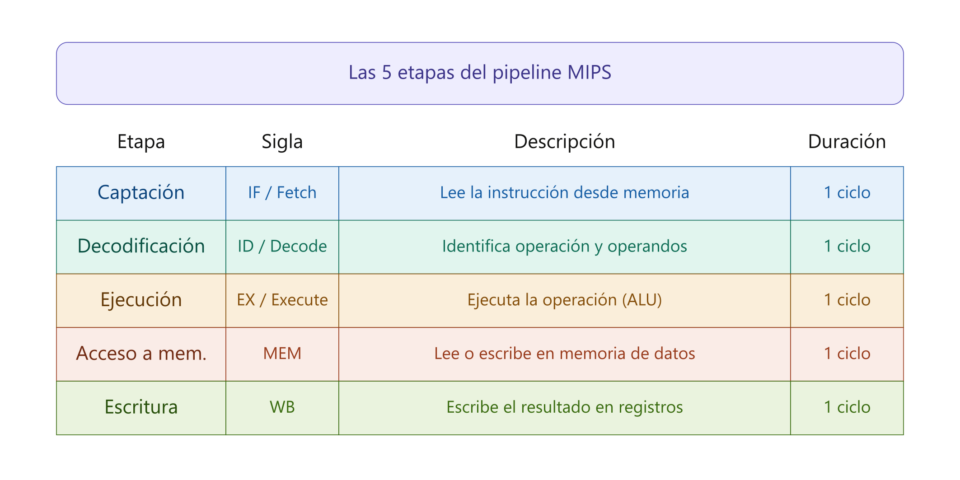
Este diseño obligó a que las CPU mejoraran drásticamente los tiempos de acceso a la memoria RAM, reduciéndolos a un solo ciclo durante la etapa de captación. Al mismo tiempo, exigió que todas las instrucciones del set fueran lo suficientemente simples y homogéneas para completarse en un único ciclo de reloj por etapa sin atascar el cauce. Gracias a esto, la segmentación permite que el rendimiento en cantidad de instrucciones ejecutadas por segundo se acerque a la velocidad de reloj. El 68000 de Motorola a 8 MHz tenía la capacidad de 1 MIPS; imaginaos microprocesadores a la misma frecuencia alcanzando casi los 8 MIPS de forma teórica.
Cuellos de botella en un microprocesador segmentado
Sobre el papel, toda CPU segmentada debería tener un rendimiento equivalente a 1 instrucción por ciclo de reloj (IPC = 1). El problema es que, a efectos reales, esto no es así y se añaden una serie de ciclos de reloj de retraso que hacen que el rendimiento real sea menor. Incluso con optimizaciones, el rendimiento nunca es del 100%, al igual que ocurre con cualquier otro sistema en el mundo real. A las causas de la pérdida de rendimiento en los microprocesadores segmentados se les llama riesgos (hazards) y existen de tres tipos distintos.
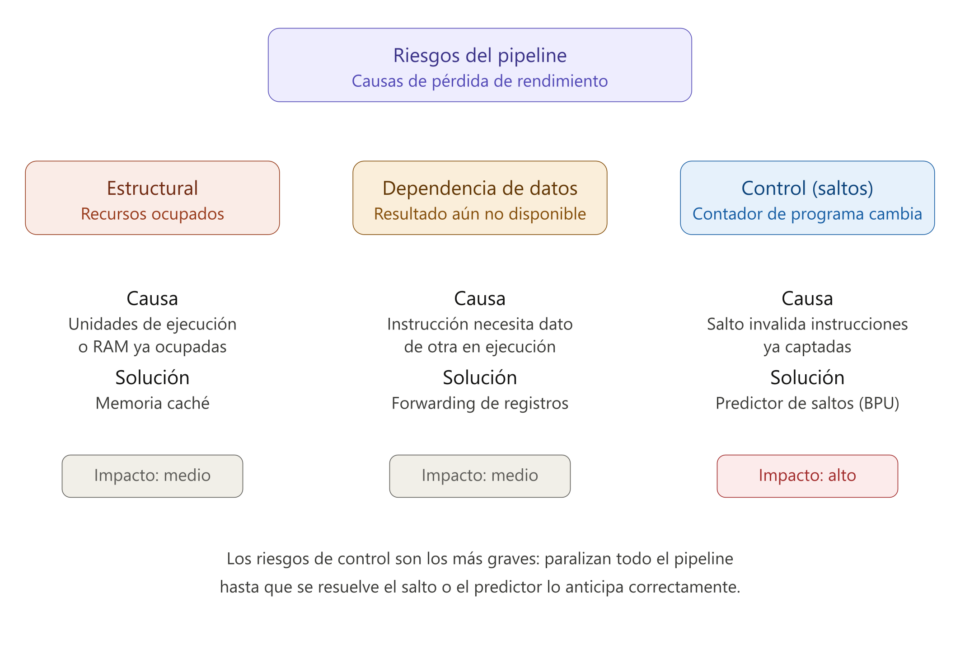
Hay que destacar que los riesgos no son exclusivos de la arquitectura MIPS, sino de la propia naturaleza de la segmentación, por lo que cualquier microprocesador que la implemente los sufre e integra soluciones por hardware o por software.
Riesgos estructurales
Ocurren cuando el hardware del chip no es suficiente para dar abasto a varias instrucciones simultáneas que solicitan el mismo recurso físico. La segmentación requiere que ciertos recursos dentro del chip se encuentren disponibles en cada momento. Si esos recursos están ocupados por instrucciones anteriores aún en ejecución, se forma un cuello de botella que detiene temporalmente el cauce (lo que se conoce como stall o burbuja).
El ejemplo que da Hennessy en su famoso libro es lo que ocurre cuando hay un solo puerto de acceso a la memoria RAM. Como se detalla en el gráfico de riesgos de arriba, si una instrucción se encuentra en su etapa MEM leyendo o escribiendo un dato de la RAM, y al mismo tiempo una nueva instrucción intenta realizar la etapa Fetch (IF) para leer el código del programa, ambas colisionan por el acceso al mismo bus. Esto forzó la implementación de memorias caché separadas (una caché para instrucciones y otra para datos), no solo para reducir la latencia general, sino para permitir accesos simultáneos y eliminar este conflicto estructural.
Riesgos de dependencia de datos
¿Qué ocurre cuando una instrucción requiere el resultado de una operación anterior que aún se está ejecutando en el pipeline? Si la instrucción dependiente avanza, leerá un dato antiguo o erróneo en la etapa ID porque la instrucción previa todavía no ha llegado a la etapa final de escritura (WB).
Para evitar la necesidad de congelar la CPU durante varios ciclos a fin de solucionar este problema, los diseñadores introdujeron una técnica de hardware conocida como adelantamiento o forwarding (bypassing).
- Consiste en añadir caminos de datos auxiliares (cables y multiplexores) que interceptan el resultado de una operación apenas sale de la ALU (etapa EX) o de la memoria (etapa MEM) y lo “inyectan” directamente en la entrada de la ALU para la siguiente instrucción, evitando esperar a que pase por la etapa WB.
- En los casos más complejos, en los que el hardware no puede salvar la distancia, el compilador tiene que intervenir reorganizando el orden de las instrucciones del código para separar las dependencias.
Riesgos de control (saltos)
Todo programa es la ejecución de una sucesión de instrucciones, pero existen las instrucciones de salto y los bucles, que hacen que el PC rompa la linealidad cuando se cumple una condición. Son los saltos los que suponen el mayor problema para una CPU segmentada.
- Dado que el procesador va captando instrucciones de forma secuencial ciclo a ciclo, cuando un salto condicional finalmente se evalúa y resulta ser verdadero, la CPU descubre que todas las instrucciones que ya ha introducido previamente en el pipeline no son las que correspondía ejecutar.
- Esto obliga a «vaciar» el pipeline por completo (hacer un flush) y desechar el trabajo realizado en esas etapas, haciendo que la nueva dirección de destino tenga que recorrer el cauce desde cero.
- La consecuencia directa de esto es que añade una penalización de varios ciclos de reloj que eleva el promedio de Ciclos Por Instrucción (CPI), un problema que los ingenieros mitigaron más adelante mediante la inclusión de unidades de predicción de saltos (Branch Prediction Units) en microprocesadores futuros.
MIPS R3000
Una vez hemos terminado el inciso sobre la segmentación en los microprocesadores, nos toca hablar del R3000, introducido en 1988 como segunda generación de la familia. Esta CPU heredó el mismo set de instrucciones (MIPS I) que su predecesor, tratándose de una versión mucho más pulida y optimizada. La cantidad de transistores en total pasó de los 110.000 a los 125.000, una cifra modesta para un salto generacional. El chip se diseñó para fabricarse utilizando un proceso más avanzado (de 2 micras a 1.2 micras), lo que redujo el tamaño del chip a tan solo 48 mm² en comparación con los 80 mm² de su antecesor. Esta reducción de escala fue clave para disparar las frecuencias de reloj, permitiendo al R3000 operar a velocidades de 20 MHz, 25 MHz, 33.33 MHz y hasta 40 MHz.

Uno de los cambios principales fue la absorción de los mecanismos propios del R2020 dentro del chip; aunque la memoria caché seguía fuera del chip, este cambio aceleró el rendimiento de las instrucciones, ya que mientras en el R2000 la caché tenía un ciclo de reloj de retraso, en el R3000 las instrucciones a memoria se realizaban en el mismo ciclo, aumentando con ello el rendimiento de la CPU, la cual llegó a alcanzar los 30 MIPS en su modelo a 33.33 MHz. Además, esto permitía a la CPU acceder a ambas cachés externas en el mismo ciclo de reloj y abrió la puerta al soporte de coherencia de datos, lo que permitió el soporte para sistemas multiprocesador en sistemas avanzados con varios R3000 trabajando en simultáneo.
En cuanto al COP0, se le añadió un TLB de 64 entradas dentro del chip para mejorar el rendimiento de la MMU; gracias a ello, la traducción de direcciones de memoria virtual a física pasó a ser instantánea, reduciendo drásticamente las temidas penalizaciones por «fallos de página» que arruinaban el rendimiento en multitarea.
MIPS III y el R4000

En el mundo de la computación orientada a aplicaciones científicas, la precisión lo es todo, por lo que una versión de 64 bits de la arquitectura MIPS se encontraba como una propuesta encima de la mesa desde los inicios de la misma. Esto se hizo realidad en 1991, cuando se introdujo el set de instrucciones MIPS III, que supuso varios cambios en la arquitectura:
- Los 32 registros pasaron de ser de 32 bits a 64 bits.
- Las ALU pasaron a poder operar con números de 64 bits.
- El direccionamiento pasó a ser de 64 bits, tanto el físico como el virtual.
- Bus de datos de 64 bits.
- Se mantuvo la compatibilidad total hacia atrás con el software para MIPS I (R2000 y R3000).
- Era posible cambiar del modo de 32 bits al de 64 bits y viceversa de forma dinámica y al vuelo con 1 bit adicional en el registro de estado.
Mejoras en la arquitectura
En el R4000 no se limitaron únicamente a hacer un R3000 de 64 bits, sino que introdujeron una serie de cambios clave para alcanzar un rendimiento mucho mayor.
- El primero de ellos fue la integración dentro del chip de la memoria caché de primer nivel, organizada en dos pozos separados de 8 KB cada uno para datos e instrucciones, lo que mejoró todavía más el rendimiento por ciclo de reloj, además de permitir el uso de un controlador de caché externo para una caché de segundo nivel.
- El segundo cambio fue la inclusión dentro del propio chip de la unidad de coma flotante, una mejora que ya se había visto en otras CPU como el 486 de Intel y el Motorola 68040. Al contrario que las unidades de coma flotante para el R2000 y el R3000, su pipeline tenía la misma longitud en etapas que en las operaciones con enteros.
- Sin embargo, el arma secreta del R4000 era su capacidad para alcanzar altas velocidades de reloj; para ello, el pipeline original de 5 etapas se aumentó de las 5 a las 8 etapas. Esto hace que cada etapa sea más simple, dure menos tiempo y requiera menos tiempo físico para completarse, elevando drásticamente el techo de velocidad del reloj, lo que le permitió alcanzar cifras por encima de los 100 MHz. El nuevo pipeline se organiza de la siguiente manera:

En este recorrido nos detenemos en MIPS III, porque a partir de MIPS IV la evolución de la arquitectura quedó mucho más vinculada a las necesidades específicas de SGI y su entorno de estaciones de trabajo avanzadas, con un impacto menos transversal en la informática general. No en vano, las familias R5000, R8000 y R10000 jamás salieron del mundo de las estaciones de trabajo de Silicon Graphics.
La compra por parte de Silicon Graphics
Al mismo tiempo que se presentaba el R4000 al mundo, uno de sus principales clientes, Digital Equipment Corporation, anunciaba su propio microprocesador RISC bajo el nombre de Alpha, abandonando con ello el soporte a las CPU MIPS, la cual perdía un cliente sumamente importante, incluso aún más que Silicon Graphics, que disponía de una cuota de mercado más pequeña. Precisamente fue la propia SGI la que entró en pánico y adquirió a MIPS Computer el 13 de marzo de 1992, convirtiéndola en una subsidiaria suya bajo el nombre de MIPS Technologies.
Esto tuvo como efecto que las CPU con set de instrucciones MIPS desarrollados por terceros que tenían una licencia previa como LSI Logic, Toshiba y otras, no pudieran utilizar las evoluciones posteriores del set de instrucciones MIPS, lo que provocó una bifurcación total en el mercado. Sin embargo, cuando en 1998 MIPS Technologies recuperó su independencia, crearon un chip que por nombre se suele confundir con el R4000, el MIPS32 R4K. ¿Su particularidad? Era una versión del R3000, pero con la capacidad de alcanzar altas velocidades de reloj a muy bajo consumo; su uso más popular fue en la PSP de Sony.
Variantes
Bajo el set de instrucciones MIPS III aparecieron varios modelos de microprocesadores distintos, algunos de ellos de la propia MIPS Technologies y otros de terceros. Los más destacados a nivel histórico son:
- El MIPS R4200, lanzado en 1992, era una variante de bajo consumo del R4000. Su uso principal fue como microprocesador embebido en routers e impresoras de alta gama, pero también en ordenadores portátiles donde destaca la gama Versa de NEC. Dicho microprocesador fue la variante del R4000 que se diseñó para funcionar bajo Windows NT.
- En cuanto al R4300 o VR4300, era una versión reducida de bajo coste del R4200, fabricada y diseñada por NEC, es popular por su uso en Nintendo 64 como CPU principal. Su particularidad es un bus reducido de datos de solo 32 bits.
- La tercera variante, R4400, fue exclusiva de Silicon Graphics y se fabricó después de la compra de MIPS Technologies en 1994, por lo que fue exclusiva de sus estaciones de trabajo. Duplico el tamaño de la caché de primer nivel y alcanzo velocidades de reloj mucho más altas, permitiendo alcanzar hasta los 250 MHz, al contrario que el R4200, no se pensó para sistemas de bajo consumo.
La caída en desgracia de la arquitectura MIPS
Su fin llegó de la mano de Silicon Graphics, la cual a lo largo de la década de los 90 se había planteado crecer mediante adquisiciones (Alias Research, Wavefront Technologies, Cray Research) que se estaban financiando con un negocio que pronto iba a ser disruptado y perdería el motivo de su existencia. La democratización del hardware lo cambió todo: a finales de la década, un PC con un Pentium II y una tarjeta 3dfx hacía lo que cinco años antes solo podía hacer una estación de trabajo SGI de 50.000 dólares. Las ventas cayeron sin remisión, y la empresa que había facturado más de 4.000 millones de dólares anuales en su pico entró en pérdidas de las que no volvió a salir.

MIPS Technologies se independizó de SGI en 1998 y sobrevivió a su caída, pero sin el músculo de su antigua matriz nunca volvió a definir el estado del arte. Lo que siguió fue una cadena de adquisiciones que resume bien el ocaso de la arquitectura: en 2013 fue comprada por la británica Imagination Technologies; en 2017 pasó a manos de Tallwood Venture Capital cuando el gobierno de EE. UU. bloqueó su venta a un fondo chino junto con Imagination; y de ahí a Wave Computing, una startup de inteligencia artificial que presentó quiebra en 2020.
La empresa emergió del concurso en 2021 rebautizada simplemente como MIPS, y el anuncio que acompañó a su salida fue la confirmación definitiva: la próxima generación de núcleos estaría basada en RISC-V, no en la ISA propia. La arquitectura que Hennessy diseñó para demostrar que menos podía ser más terminó cediendo ante algo todavía más radical: una ISA que ni siquiera cobra por usarse. Cuatro décadas después de aquel laboratorio de Stanford, el legado de MIPS no vive en ningún chip con su nombre, sino en cada procesador segmentado que existe sobre la tierra.